
[DL] 1. 합성곱 신경망(Convolutional Neural Network, CNN) - 컨볼루션 및 풀링 계층
CNN 레이어의 여러 단계 중, Convolution/Pooling에 대해 알아본다.
CNN 은 이미지 분류에 유용하게 사용되는 기술이다. CNN은 1989년 LeCun이 발표한 논문 “Backpropagation applied to handwritten zip code recognition” 에서 처음 소개되었다. 그 당시에는 필기체 인식에 있어 의미있는 결과가 나왔지만 이를 범용화하는데엔 미흡한 부분이 있었다. LeCun은 추후에 LeNet이라는 네트워크를 1998년에 제안하게 되는데 이것이 최초의 CNN 이라고 할 수 있다.
1. 합성곱 신경망(CNN)이란?
합성곱 신경망(Convolutional Neural Network, CNN) 은 이미지 인식, 이미지 분류를 수행하는 주요 신경망 기술이다.

Convolutional layers로 구성된 신경망 (출처 : Medium, Prabhu)
- 위 그림은 입력 이미지를 처리하고 값을 기준으로 개체를 분류하는 CNN의 전체 흐름이다.
- 입력 이미지는 필터(Filters), 풀링(Pooling), 완전연결 계층(Fully connected layer, FC)이 있는 일련의 Convolution Layer를 통과하고 Softmax 함수를 적용하여 0과 1 사이의 확률 값으로 개체를 분류한다.
2. 합성곱 신경망(CNN)의 필요성
합성곱 신경망은 이미지 처리에 탁월한 성능을 보이는 신경망이다. 특히 이미지 처리를 위해 사용되는 다층 퍼셉트론(MLP)의 한계를 보완할 수 있다.
예를 들어, 손글씨를 분류해야하는 상황에서 아래 알파벳이 입력값으로 들어온다고 가정해본다. 아래 6개의 d 손글씨의 input shape는 (10, 10, 1)이라고 가정한다.

손글씨, 알파벳 'd' 이미지 (GoodNotes로 제작)
사람이 보기엔 위 그림이 모두 알파벳 ‘d’로 쉽게 판단이 가능하지만, 기계가 보기에는 각 픽셀마다 가진 값이 대부분 상이하므로 사실상 다른 값을 가진 입력이다. 특히 이미지가 위와 같이 방향이 다르거나 한쪽으로 치우쳐져 있는 등 변형이 존재한다면 다층 퍼셉트론(MLP)로 예측하는데 어려움이 있다.
cf. 다층 퍼셉트론은 입력층으로 1차원 벡터를 사용해야 함
위 손글씨 이미지 중 네 번째 글씨를 1차원으로 변환해보았다. 아래 과정과 같이 2차원 이미지를 1차원으로 변환하게 되면 변환 전에 가지고 있던 공간적인 구조(Spatial Structure) 정보가 유실된다.
- 공간적인 구조 : 가까운 픽셀 간의 관계
- 예 : ‘d’는 동그란 부분과 막대기 부분이 붙어 있는데, 막대기의 왼쪽 아래부분에 연결되어있다.
- 이러한 구조가 1차원 배열로 변환되면 그러한 공간적 구조의 특징을 잃게 됨

손글씨, 알파벳 'd' 이미지의 1차원 변환 과정 (GoodNotes, PowerPoint로 제작)
위와 같은 ‘공간적 구조’ 문제 때문에 이미지의 공간적인 구조 정보를 보전하면서 학습할 수 있는 방법이 필요해졌고, 이를 위해 합성곱 신경망이 사용된다.
3. 합성곱 신경망(CNN) 관련 용어
Conv2D의 기본 구조 : Conv2D(filters kernel_size, padding, strides, input_shape, activation)
(1) 컨볼루션 계층(Convolution Layer)
컨볼루션은 입력 이미지에서 특징을 추출하는 첫 번째 레이어이다. 컨볼루션은 입력 데이터의 작은 사각형을 사용하여 이미지 기능을 학습하여 픽셀 간의 관계를 유지한다. 이미지 매트릭스와 필터 또는 커널과 같은 두 개의 입력을 받는 수학적 연산이다.
✔️ 목표
- 주변 픽셀 간의 관계를 유지하면서 이미지에서 특징 집합을 추출한다.
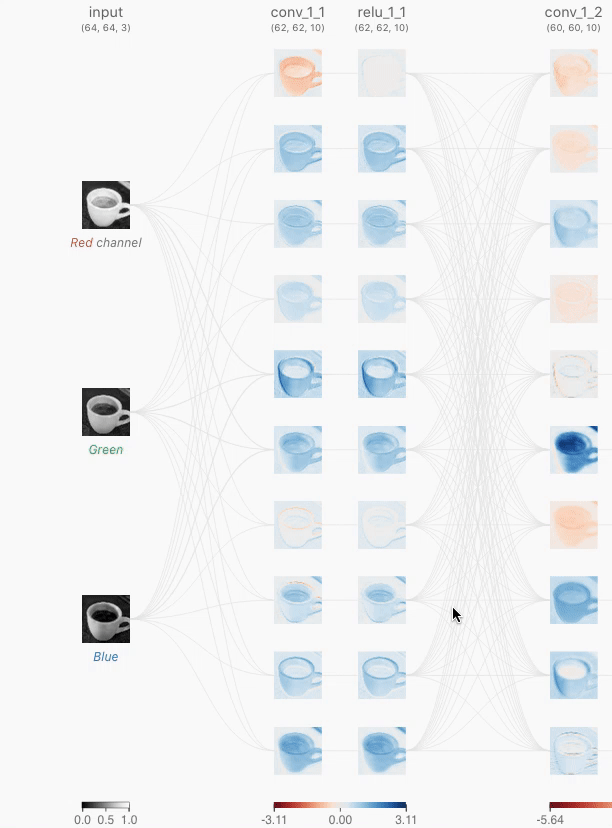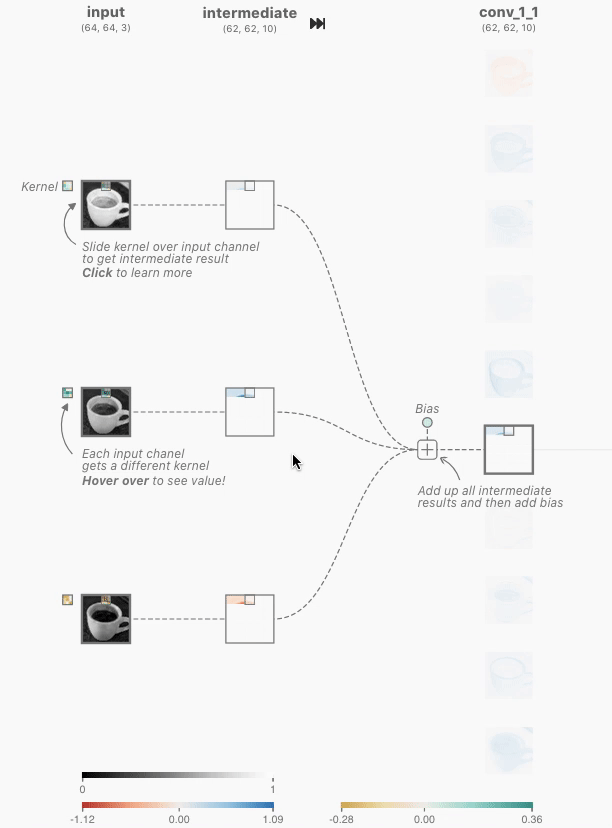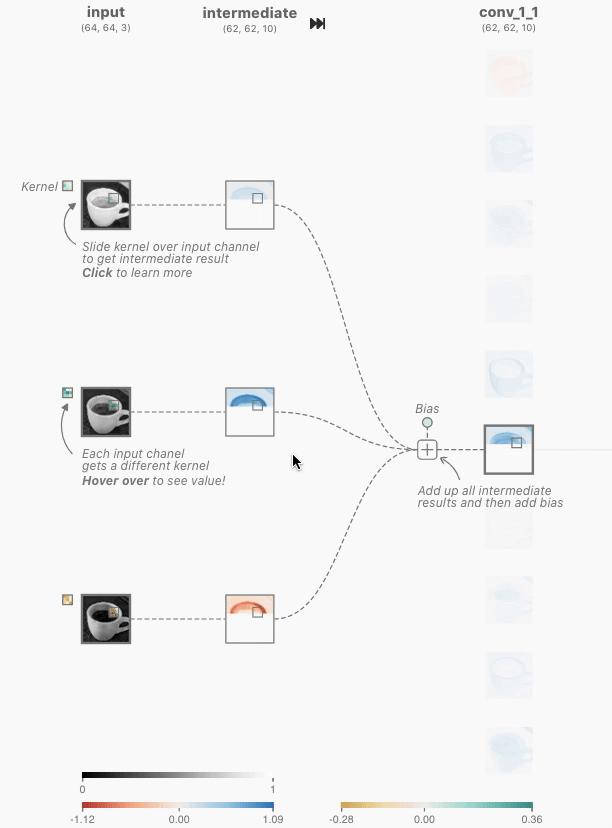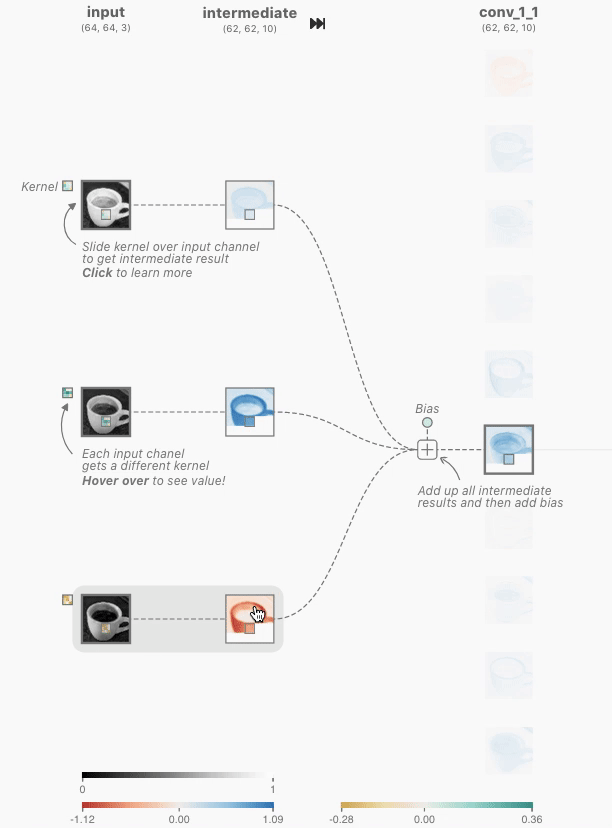
그림 1, 출처 : https://poloclub.github.io/cnn-explainer/#article-input
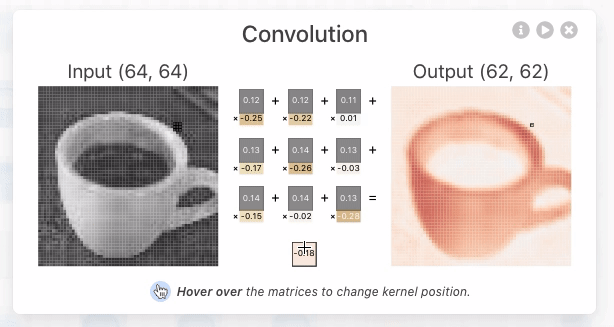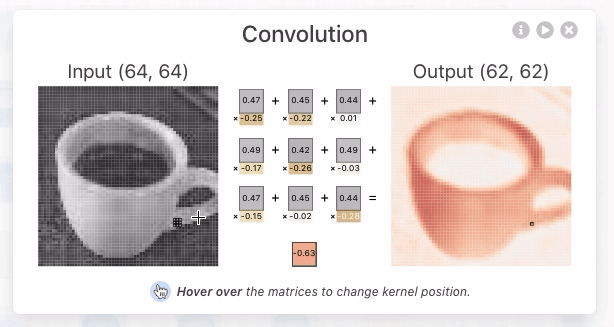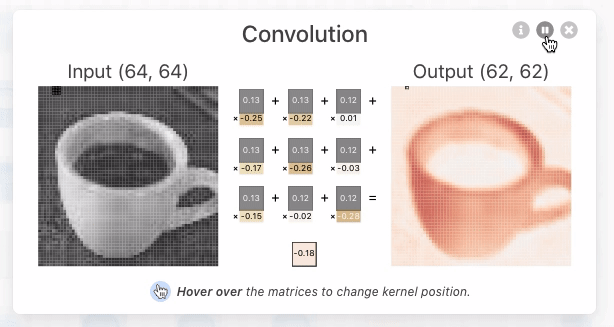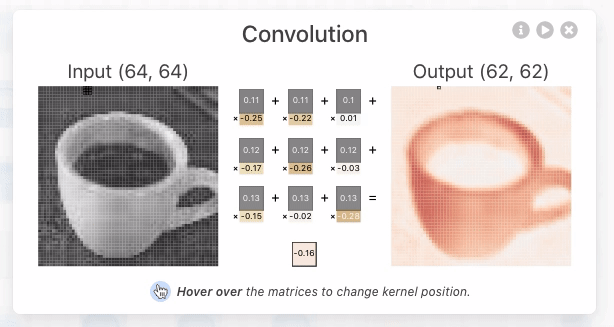
그림 2, 출처 : https://poloclub.github.io/cnn-explainer/#article-input
위 그림 2에서 중간에 있는 숫자들 아래(노란색) 부분은 랜덤하게 정해지는 가중치 값이다.
그림 2에서 이루어지는 컨볼루션 연산은 아래와 같은 방식으로 이루어진다.

이미지 출처 : towardsdatascience by Rukshan Pramoditha - CNN
- 컨볼루션 작업은 이미지와 필터 사이에서 발생한다.
- 연산을 결과로 피처맵(Feature map)이 출력된다.
- 필터 크기(kernal_size)에 따라 출력되는 피처맵의 크기가 달라진다.
(2) 채널(Channel)
CNN 이미지 분류는 입력 이미지를 가져와 처리하고 특정 카테고리로 분류되는데, 컴퓨터는 입력 이미지를 픽셀 배열로 보고 이미지 해상도에 따라 달라진다. RGB 이미지에는 세 가지 색상 채널(Red, Green, Blue)이 있으며 (height, width, 3)으로 표현된다.
cf. 이미지 해상도 hxwxd(h=높이, w=너비, d=치수)

Grayscale image, RGB color image 표현법 (powerpoint로 제작)
- 이미지는
(높이, 너비, 채널)로 표현되는 3차원 텐서임- 높이 : 이미지의 세로 방향 픽셀 수
- 너비 : 이미지의 가로 방향 픽셀 수
- 채널 : 색 성분
- 흑백 이미지 (채널 수 : 1)
- 컬러 이미지 (채널 수 : 3)
예시로 이해하기
- 데이터 정보 : Tensorflow 튜토리얼 (MNIST)
# 필요한 라이브러리 로드
import pandas as pd
import tensorflow as tf
# 텐서플로우 내장 데이터셋 : MNIST 로드
mnist = tf.keras.datasets.mnist
# 색상 표현 구간을 0 ~ 1사이로 변환(정규화)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 특정 데이터 시각화 (임의의 값 출력)
display(pd.DataFrame(x_train[4]).style.background_gradient(cmap='gray'))

28*28 픽셀의 숫자 '9' 손글씨 데이터
숫자 ‘9’ 손글씨 데이터는 흑백 이미지이므로 (28, 28, 1)의 크기를 가지는 3차원 텐서이다. 정규화 전엔 하나의 픽셀 당 0 ~ 255 사이의 값(큰 값)으로 구성된다. 색을 나타내는 범위가 크면 연산 과정에서 속도(연산) 문제가 발생할 수 있기 때문에 0 ~ 1 사이의 값으로 변환했다.
(3) 필터(Filter)/커널(Kernel)
필터는 이미지의 특징을 찾아내기 위한 파라미터로 학습의 대상이며, 합성곱의 가중치에 해당한다.
- 필터(Filter) : 실제로 커널이 가중치 합산 하는 영역의 크기
- 커널(Kernel) : Sliding window 하는 영역에서의 크기

출처 : ResearchGate Fig 1 - uploaded by Miguel Nicolau
작은 필터를 여러 개 중첩하면 원하는 특징이 더 돋보이게되면서 연산량이 줄어드는 효과가 있다. 요즘 대부분의 CNN 에서 3 * 3 size를 중첩해서 사용한다.
cf. 학습된 CNN 필터들은 경계선을 찾거나 블러리한 면을 찾는 등 다양한 주파수 필터의 기능을 한다.
(4) 패딩(Padding)
Padding은 Convolution을 수행하기 전, 입력 데이터 주변을 특정 픽셀 값으로 채워 늘리는 것이기 때문에 입력 이미지의 크기를 줄이지 않을 수 있다.
✔️ 목표
- 이미지가 줄어드는 현상 방지
- 가장자리(모서리) 부분에 위치한 정보들이 사라지는 문제를 해결하기 위해 사용됨
- 가장자리 부분의 특징을 조금 더 학습할 수 있도록 함
(5) 스트라이드(Stride)
스트라이드는 필터를 적용하는 간격을 의미한다. 필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산한다! stride가 1이라면 필터를 한 번에 한 픽셀씩 이동하고 stride가 2라면 필터는 2칸씩 이동하면서 합성곱을 계산한다.
✔️ 주의
- stride를 높일 수록 공간적으로 더 작은 출력 볼륨이 생성되어 데이터 손실 우려가 있음
- 즉, 이 값이 커지게 되면 결과 데이터의 사이즈가 작아짐
- 데이터 손실 문제 발생

출처 : https://excelsior-cjh.tistory.com/79
위 그림은 1폭 짜리 zero-padding과 stride 값으로 1로 적용한 뒤 합성곱 연산을 수행하는 예제이다.
(6) 풀링 계층(Pooling Layer)
풀링 계층은 CNN에서 사용되는 두 번째 레이어 유형이다. CNN에는 풀링 레이어가 여러개 있을 수 있다. 컨볼루션과 풀링레이어는 쌍으로 함께 사용된다.
Pooling을 하면 이미지 크기를 줄여 계산을 효율적으로 할 수 있고 데이터를 압축하는 효과가 있어 오버피팅을 방지할 수 있다. (이미지를 추상화하여 너무 자세히 학습되지 않도록 하여 오버피팅 방지)
✔️ 목표
- 이미지의 크기를 계속 유지한 채 FC 레이어로 가게 되면 연산량이 기하급수적으로 늘게 된다.
- 적당히 크기를 줄이고, 특정 feature를 강조할 수 있도록 함
- 이전 컨벌루션 계층에서 반환된 출력의 차원(픽셀 수)을 줄인다.
- 네트워크의 매개변수 수를 줄인다.
- 이전 컨벌루션 계층에서 추출한 피처에 있는 노이즈를 제거한다.
- CNN의 정확도를 높인다.
✔️ 종류
- MaxPooling : 가장 큰 값을 반환
- AveragePooling : 평균 값을 반환
- MinPooling : 최솟값을 반환

이미지 출처 : https://gruuuuu.github.io/machine-learning/cnn-doc/
CNN에서는 뉴런이 가장 큰 신호에 반응하는 것과 유사하다는 점에서 Max Pooling을 주로 사용한다. Max Pooling을 사용하면 노이즈가 감소하고 속도가 빨라지며 영상의 분별력이 좋아진다고 한다.
✔️ Reference
- 멋쟁이사자처럼 AI 스쿨 - 박조은 강사님 강의자료
- Medium by Rukshan Pramoditha - Convolutional Neural Network (CNN) Architecture Explained in Plain English Using Simple Diagrams
- 깃헙블로그 by GRU - 호다닥 공부해보는 CNN(Convolutional Neural Networks)
- 깃헙블로그 by Taeyoung, Kim - 컨볼루션 신경망 레이어 이야기
- 티스토리 by Excelsior-JH - 합성곱신경망(CNN, Convolutional Neural Network)
- 티스토리 by 고뭉나무 - [딥러닝 모델] CNN (Convolutional Neural Network) 설명
- 벨로그 by tobigs_xai - [2주차] CNN 필터 시각화 (CNN Filter Visualization
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기