
[ML] 의사결정나무(Decision Tree) - CART(분류 및 회귀 트리)
결정 트리(Decision Tree)
- 분류, 회귀, 다중출력 작업이 가능한 알고리즘
- 랜덤포레스트(Random Forest)의 구성요소, 즉 결정트리의 집합이 랜덤포레스트이다.
- 결정트리가 모여 랜덤 포레스트를 구성 함
용어 정리
- 노드(Node) : 결정 트리에서 질문이나 정답을 담은 네모 상자
- 루트 노드(root node) : 맨 꼭대기의 노드
- 부모 노드(parent node) : 자식노드를 가지는 노드
- 자식 노드(child node) : 부모가 있는 노드
- 리프 노드(leaf node or Terminal Node) : 자식을 가지지 않는 노드 (맨 마지막 노드)

결정 트리 학습법(Decision Tree Learning)
- 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측모델로서 결정 트리를 사용
- 예측 모델링 방법 중 하나이다
결정 트리 학습법을 사용하는 이유?
- 결과를 해석하고 이해하기 쉬움
- 자료를 가공할 필요가 거의 없음
- 수치 자료와 범주 자료 모두에 적용 가능
- 화이트 박스 모델을 사용
- 안정적 (모델 추리의 기반이 되는 명제가 다소 손상되었더라도 잘 동작 함)
- 대규모의 데이터 셋에서도 잘 동작 함
- 최근 가장 인기있는 알고리즘
👉단점 : 훈련 데이터에 과대적합(Overfitting), 과소적합(Underfitting) 되는 경향
👉해결법 : 랜덤포레스트로 해결 가능
결정 트리 학습법의 종류?
- 분류 및 회귀 트리
- CART(Classification And Regression Tree) 는 두 트리를 아울러 일컫는 용어
- 두 트리는 일정 부분 유사하지만, 입력 자료를 나누는 과정에서 차이점이 있음
- 앙상블 방법
- 한 개 이상의 결정 트리 생성
- 여러 결정트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 정함 (다수결 원칙)
- 이렇게 의견을 통합하거나 여러 가지 결과를 합치는 방식이 앙상블(Ensemble)
(1) 분류 트리
- 트리 모델 중 목표 변수가 유한한 수의 값을 가짐
- 예측된 결과로 입력 데이터가 분류되는 클래스를 출력
# 분류 트리
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# 학습
clf.fit(X_train, y_train)
# 예측
clf.predict(X_test)
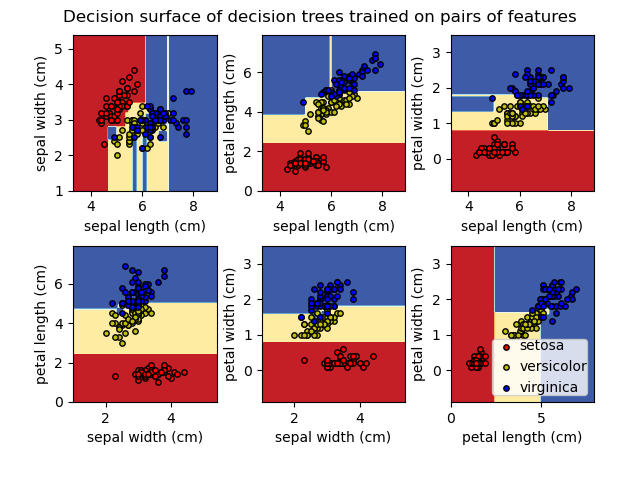
(2) 회귀 트리
- 결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가짐
- 예측된 결과로 특정 의미를 지니는 실수 값 출력 (예: 주택 가격, 환자 입원 기간)
# 회귀 트리
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
# 학습
clf.fit(X_train, y_train)
# 예측
clf.predict(X_test)
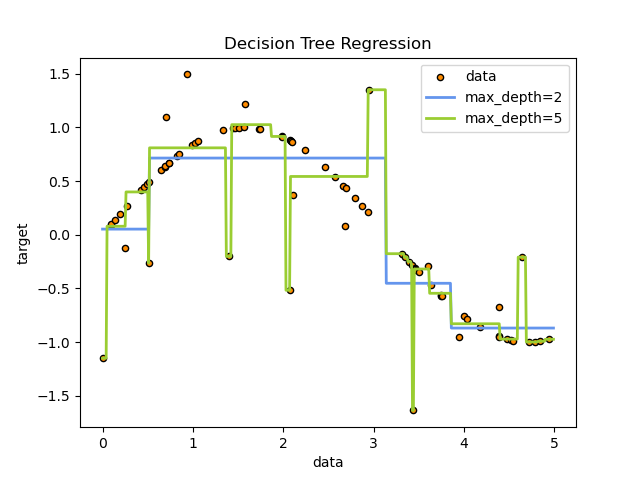
(3) CART의 주요 파라미터
- criterion : 가지의 분할의 품질을 측정하는 기능
- max_depth : 트리의 최대 깊이
- min_samples_split : 내부 노드를 분할하는 데 필요한 최소 샘플 수
- min_samples_leaf : 리프 노드에 있어야 하는 최소 샘플 수
- max_leaf_nodes : 리프 노드 숫자의 제한치
- random_state : 추정기의 무작위성을 제어하고 실행했을 때 같은 결과가 나오도록 함
- max_features : 최적의 분할을 위해 고려하는 특성의 개수 (int:개수, float:비율)
Reference
- [위키백과, 우리 모두의 백과사전] - 결정 트리 학습법
- [귀퉁이 서재 Tistory] - 머신러닝 4. 결정 트리(Decision Tree)
- [yg’s blog] - [Handson ML] 의사결정나무(Decision Tree)
- [scikit 공식 문서] - sklearn.tree.DecisionTreeRegressor
- 📷 Fig 1. 이미지 출처 : [텐서플로우 블로그 (Tensor ≈ Blog)] 2.3.5 결정 트리
- 📷 Fig 2, 3. 이미지 출처 : [scikit 공식 문서] - 1.10. Decision Trees
개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다 :)
댓글남기기