
[ML] 랜덤 포레스트(Random Forest)
앙상블 학습 방법의 일종인 랜덤 포레스트에 대해 알아본다.
✔️ 랜덤포레스트
랜덤 포레스트의 포레스트는 숲(Froest) 입니다. 결정 트리의 트리는 나무(Tree) 입니다. 즉, 결정 트리(Decision Tree)가 모여 랜덤 포레스트(Random Forest)를 구성합니다.
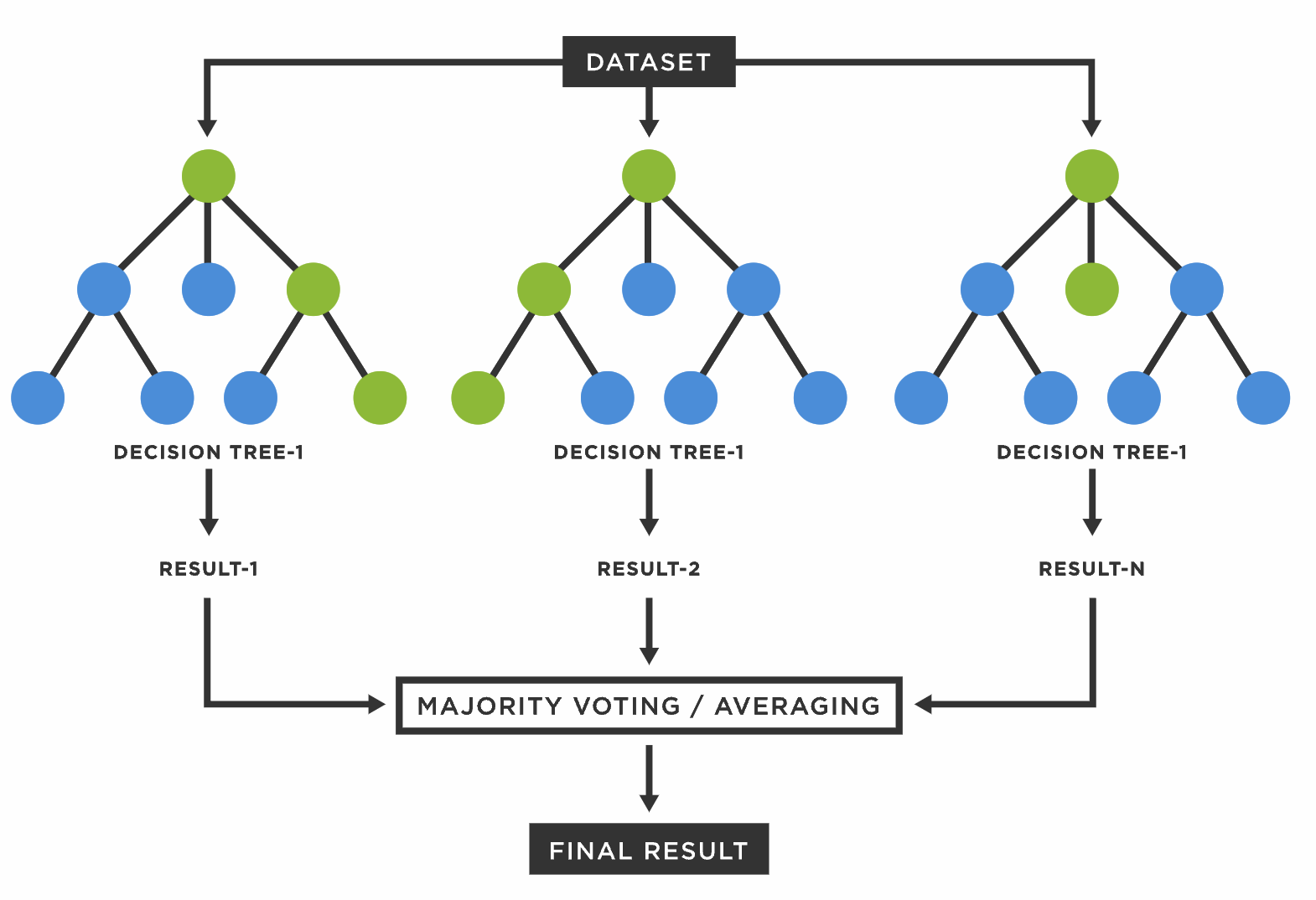
1. 의사결정나무와 랜덤포레스트의 차이
결정 트리(Decision Tree) 하나만으로 머신러닝 모델을 만들 수 있지만, 랜덤 포레스트(Random Forest)를 사용하는 이유는 뭘까요?
결정 트리는 훈련 데이터(Train Data)를 그대로 사용한다는 점에서 훈련 데이터에 너무 오버피팅(Over-Fitting) 되는 경향이 있습니다. 이러한 이유로 여러 개의 결정 트리를 통해 랜덤 포레스트를 만들면 한 데이터셋에 오버피팅 되는 단점을 해결할 수 있습니다.
2. 랜덤포레스트의 원리
어떤 결과를 예측하기 위해 수많은 요소(Feature) 를 고려해야합니다. 하지만 한 번에 수많은 요소들을 기반으로 결과를 예측한다면 분명 오버피팅이 될 것입니다.
하지만 전체 Feature를 한번에 사용하지 않고 랜덤으로 n개씩 선택하여 하나의 결정 트리를 만들고, 또 전체 요소에서 랜덤으로 n개를 선택해서 또 다른 결정트리를 만든다면 여러개의 결정 트리를 만들 수 있습니다. 그리고 결정 트리 하나마다 예측 값을 내놓고, 전체 결정 트리들이 내린 예측 값들중 가장 많이 나온 값을 최종 예측값으로 정합니다.
이렇게 의견을 통합하거나 여러 가지 결과를 합치는 방식이 앙상블(Ensemble) 이라고 합니다.

3. 랜덤포레스트의 장단점
- 장점
- 분류(Classification) 및 회귀(Regression) 문제에 모두 사용이 가능함
- 대용량 데이터 처리에 효과적임
- 과대적합 문제를 최소화하고 모델의 정확도를 향상시킴
- 단점
- 수백개에서 수천개의 트리를 형성하기때문에 예측하는데 시간이 오래 걸림
- 생성하는 모든 트리 모델을 다 확인하기 어렵기에 해석 가능성이 떨어짐
✔️ 랜덤포레스트 사용법
랜덤 포레스트는 파이썬 라이브러리 scikit-learn을 사용하면 쉽게 구현할 수 있습니다.
1. 분류(Classifier)
라이브러리는 사이킷런, ensemble의 RandomForestClassifier로 불러올 수 있다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
classifier = RandomForestClassifier(n_estimators = 100)
classifier.fit(X_train, y_train)
y_predict = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_predict)
print(f"모델의 정확도 : {accuracy}")
2. 회귀(Regressor)
라이브러리는 사이킷런, ensemble의 RandomForestRegressor로 불러올 수 있다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
regressor = RandomForestRegressor()
regressor.fit(X_train, y_train)
y_predict = regressor.predict(X_test)
# test 데이터셋에 정답값(label)이 없다면 y_train과 y_predict로 오차를 측정해볼 수 있음
mse = np.sqrt(mean_squared_error(y_train, y_predict))
rmse = mse ** 0.5
r2 = r2_score(y_train, y_predict)
print(f"평균 제곱근 오차 : {mse}")
print(f"평균 제곱근 편차 : {rmse}")
print(f"회귀계수 : {r2}")
✔️ 랜덤포레스트 주요 파라미터
min_samples_split:- 분할하기 위한 최소한의 샘플 수 (오버피팅을 제어하는데 사용)
default=2, 작게 설정할 수록 가지 수가 많아져 오버피팅 가능성이 높아짐
min_samples_leaf:- 말단 노드가 되기 위한 최소한의 샘플 데이터 수
- 오버피팅 제어하는데 사용
max_features:- 최적의 분할을 위해 고려하는 최대 특성 개수
default=None으로 모든 특성을 고려함int형 지정시 개수,float형 지정시 비율sqrt, auto, log옵션이 존재
max_depth:- 트리의 최대 깊이를 규정
default=None으로 완벽하게 클래스가 결정될 때까지 분기
max_leaf_nodes:- 말단 노드의 최대 개수
criterion:- 가지가 분할할 때의 품질을 측정하는 기능
default='gini'(지니계수)
random_state:- 추정기의 무작위성을 제어
- 실행했을 때 같은 결과가 나오도록 설정할 수 있음
✔️ Reference
- scikit-learn 공식문서
- 위키백과, 랜덤 포레스트
- ACODOM, Random Forest
- 아무튼 워라벨, 랜덤 포레스트(Random Forest) 쉽게 이해하기
- 티스토리 by 귀퉁이 서재, 머신러닝 - 5. 랜덤 포레스트(Random Forest)
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기