
[비즈니스 분석] Python으로 US E-commerce 데이터 분석하기 - EDA
목표: Kaggle의 ‘United States E-Commerce records 2020’ 데이터셋으로 RFM 분석하기 전, EDA를 진행한다.
🚨 warning
‘주문일자(Order Date)’의 자료형 변경 과정에 이슈가 있다. ‘일-월-연도’ 형태의 주문일자를 datetime로 변환하는 과정에서 일부 날짜가 ‘월(month)’과 ‘일(day)’의 위치가 바뀌어 저장되었다. 문제 발견 및 해결 과정은 ‘SQL로 미국 이커머스 데이터 분석하기’ 에 자세히 기록하였다.
프로젝트 목적
- ‘2020년 미국의 E-커머스 판매 데이터’를 사용하여 자사 서비스의 매출을 증가시킬 수 있는 방법을 고안해 본다.
- 유저의 구매 데이터를 기반으로 RFM 분석을 하고, 이를 바탕으로 인사이트와 액션을 제안해 본다.
1. 데이터, 라이브러리 로드
분석에 필요한 라이브러리를 로드한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 그래프 그릴 때, 한글지원
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'
Kaggle에서 다운받은 파일을 로드한다.
df = pd.read_csv('US_E_commerce_records_2020.csv', encoding='windows-1252')
🚨 인코딩 이슈
다운받은 데이터를 아래와 같이 불러오면 다음 에러 메시지가 출력된다.
df = pd.read_csv('US_E_commerce_records_2020.csv')
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xa0 in position 8587: invalid start byte
에러 해석
utf-8 방식으로 디코딩할 수 없고 위치가 8587의 바이트가 0xa0라는 의미이다. 이때 0xa0는 hexadecimal(16진수)로 표현된 ‘줄바꿈 하지 않는 공백(non-breaking space, NBSP)’이다. 특정 위치에 공백의 기호가 0xa0로 들어가있어서 utf-8 방식으로 디코드할 수 없다는 뜻이다. 이를 해결하기 위해 확장된 ASCII 에 널리 사용되는 windons-1252를 사용하면 된다.
2. 데이터 확인
데이터가 어떻게 구성되어있는지 확인하기 위해 데이터 프레임에서 가장 앞에 있는 5개의 행을 출력한다.
df.head()

데이터를 보면 알 수 있듯이 주문 일자가 문자열 형태로 ‘일-월-연도’로 저장되어있다. 빨간색 테두리로 감싸진 부분을 보면 주문일자, 주문번호, 고객id가 같은 것을 알 수 있다. 즉 한 고객이 같은 날 여러 물건을 주문하면 주문한 물건마다 행으로 저장된다는 것을 알 수 있다. 예를 들어 장바구니에 들어간 고기와 양파를 주문한다면 고기에 대한 주문 데이터, 양파에 대한 주문 데이터가 따로 들어간다.
# 데이터가 어떻게 구성되어있는지 확인하고 각 열들의 자료형을 확인한다.
df.info()
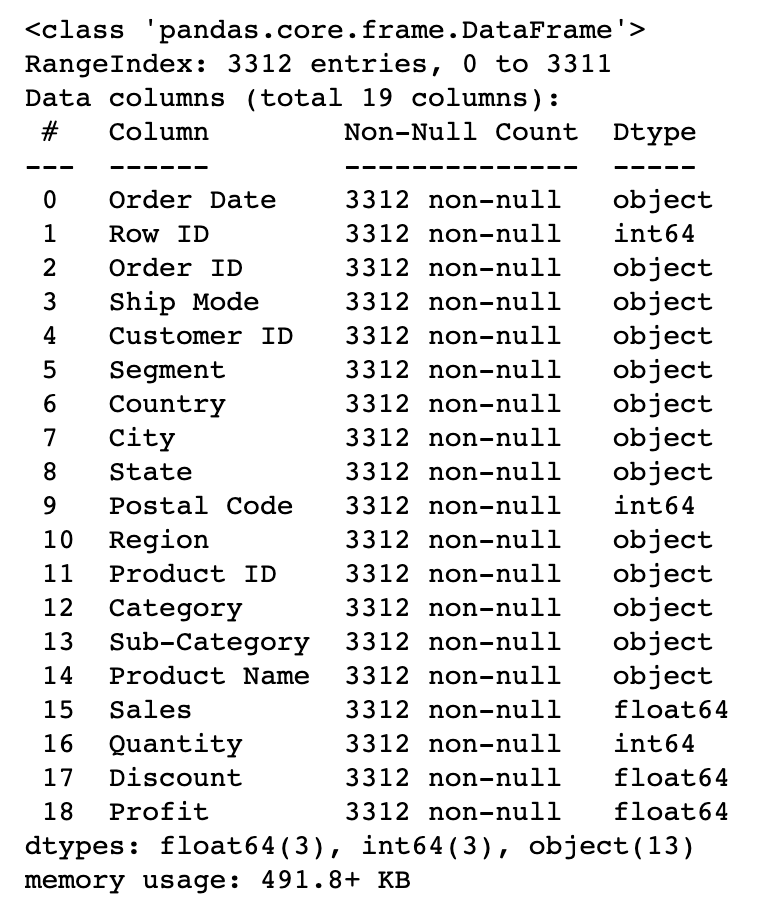
총 19개의 열, 3312개의 행으로 이루어져있으며 모든 열에 대해 결측치는 없다.
2-1. Attribute Information
- Order Date : 주문 일자
- Row ID : 행에 대한 id
- Order ID : 주문건에 대한 id
- Ship Mode : 배송 등급(Standard Class/Second Class/First Class/Same Day)
- Customer ID : 고객의 고유 id
- Segment : 고객의 타입(Consumer/Corporate/Home Office)
- Country : 고객의 국가
- City : 고객의 도시
- State : 고객의 주
- Postal Code : 고객의 우편변호
- Region : 고객이 위치한 지역
- Product ID : 제품의 아이디
- category(3)-subcategory(2)-고유아이디 순으로 제품의 아이디가 결정됨
- Category : 제품의 1차 분류 카테고리(Office Supplies/Furniture/Technology)
- Sub-Category : 제품의 1차 분류 카테고리를 기반한 상세 카테고리
- Product Name : 제품의 이름
- Sales : 판매가
- Quatity : 구매 수량
- Discount : 할인율
- Proit : 매출에 대비한 순 이익
3. 기술 통계
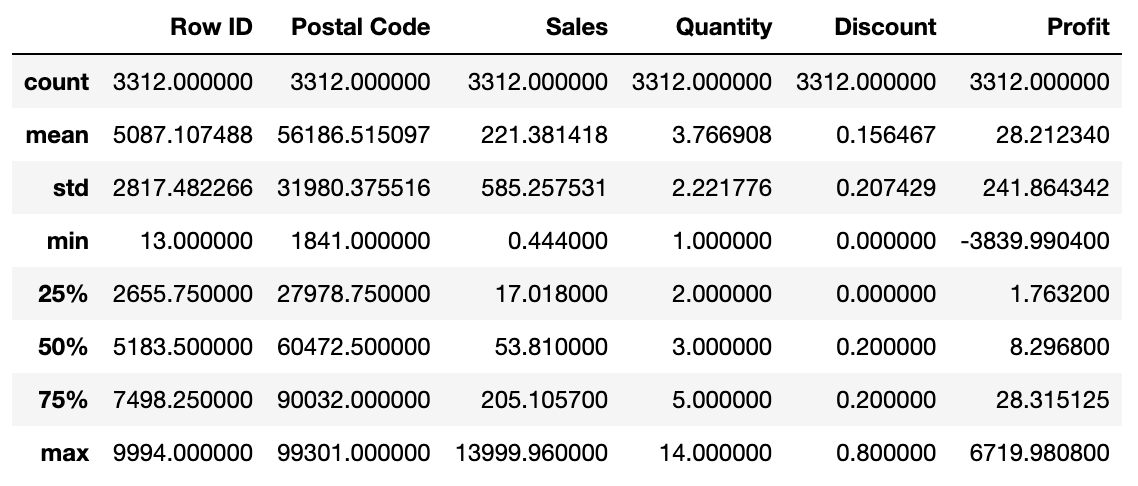
# 수치 타입의 기술통계를 구한다.
df.describe()
# 문자열 타입의 기술통계를 구한다.
df.describe(include="O")

- 순이익(Profit)은 -값 또는 +값이 될 수 있다.
- 주문 id의 nunique 값(1687)은 사용자가 1개 이상의 물품이 담긴 장바구니를 구매횟수를 의미한다.
- Country가 United States 뿐이라는 점에서 해외 배송이 이루어지지 않는 사이트임을 알 수 있다.
- 3312건에 대한 데이터는 694명의 회원에 의해 판매된 것이다.
- 판매되고 있는 주요 물품은 사무용품으로 판매의 약 60%를 차지한다. 그 중 바인더가 주 판매 물품인 것으로 보인다.
4. 히스토그램
# 전체 수치변수 시각화
df.hist(bins=20, figsize=(8, 8))
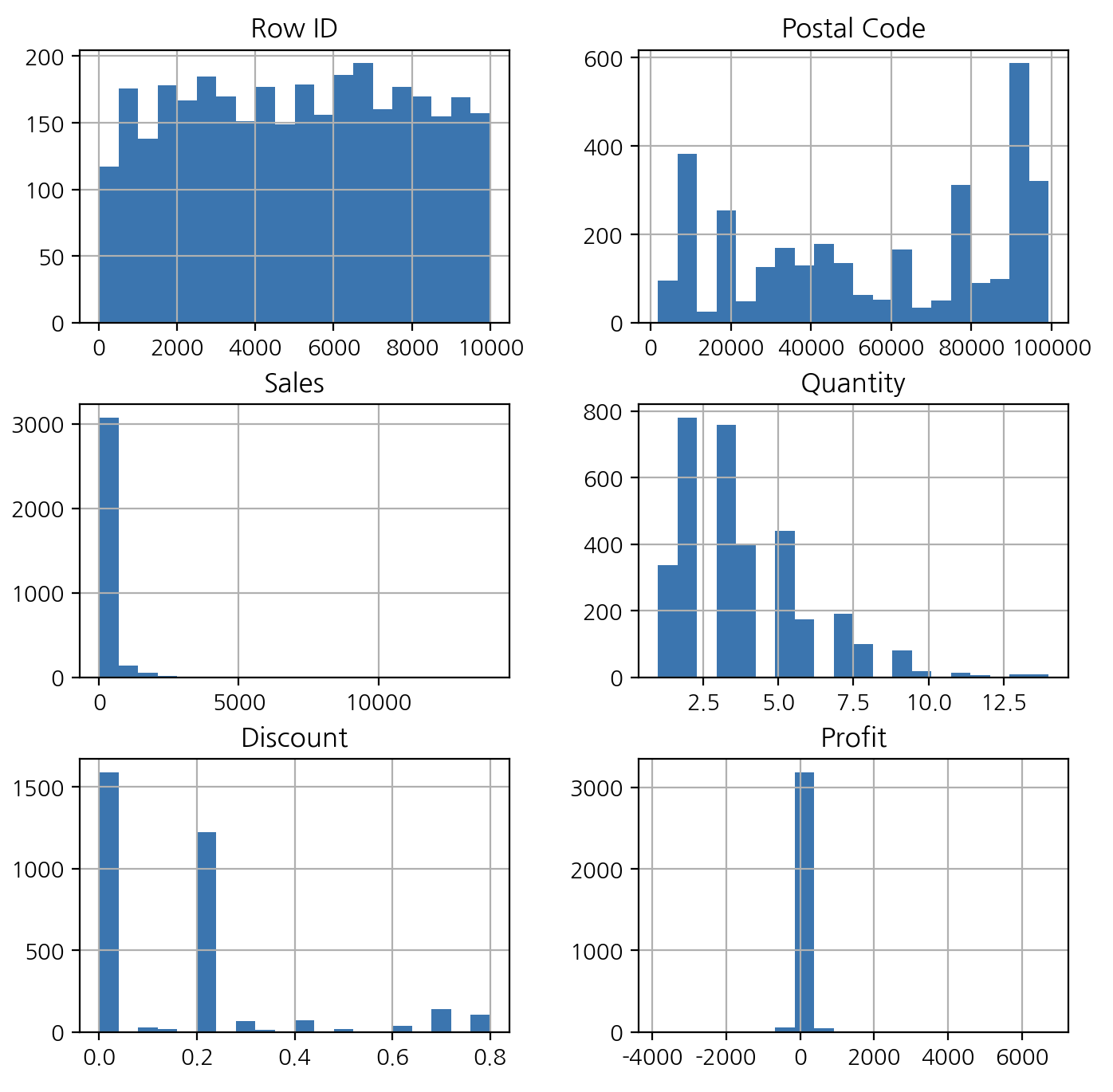
- 주문수량(Quantity)를 보면 한 종류의 물품에 대해 12개 이상을 주문한 케이스도 있음을 알 수 있다.
- 할인율(Discount)가 0인 경우가 가장 많지만 0.8 정도의 할인율로 구매한 이력도 있음을 알 수 있다.
- 순 이익(Profit)은 0 부근에 밀집되어있으나 -인 경우도 있음을 알 수 있다.
5. 날짜에 대한 파생변수 생성
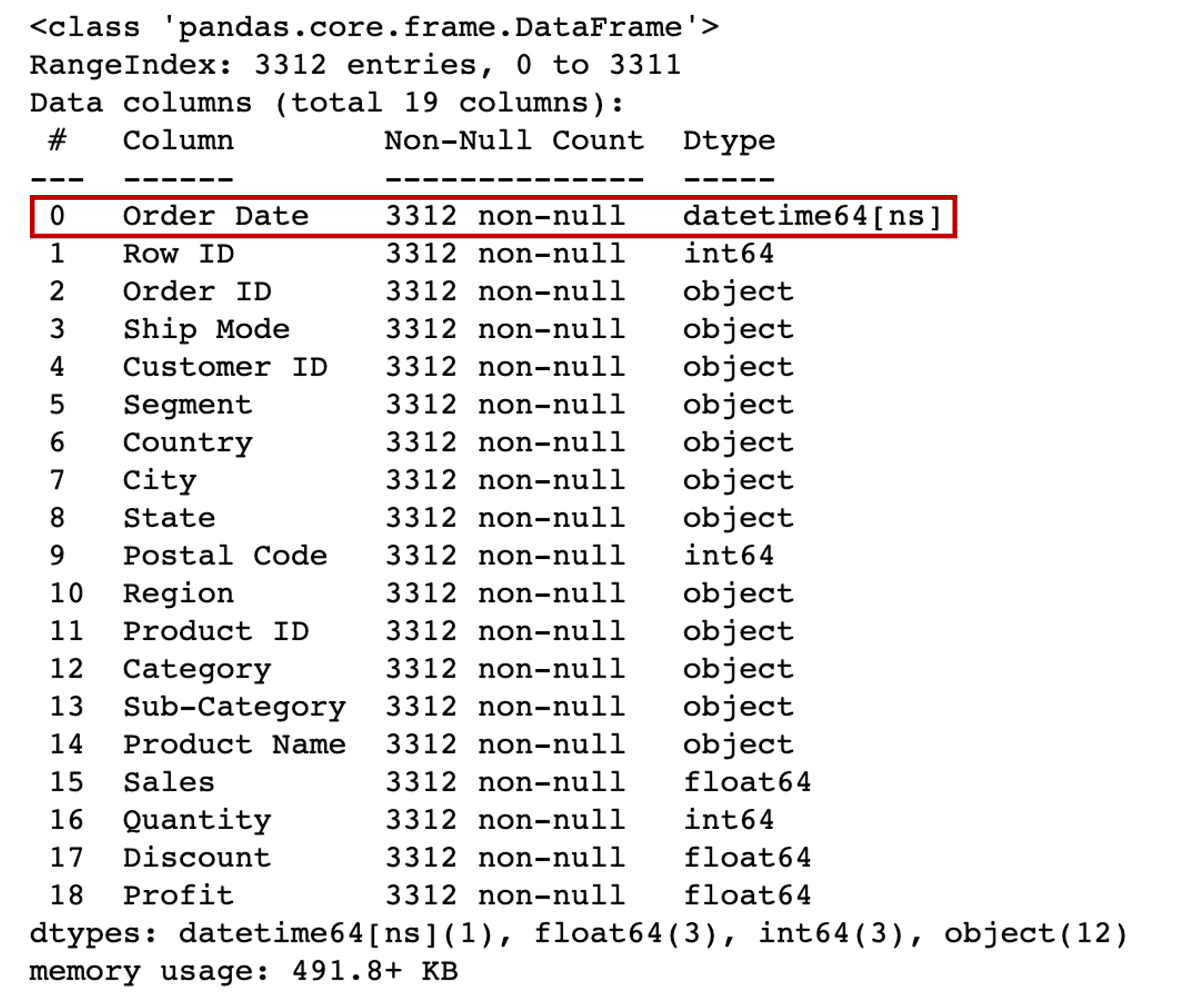
# 주문일자가 문자열 타입으로 저장되어있기 때문에 자료형을 날짜타입으로 변경
df['Order Date'] = pd.to_datetime(df['Order Date'])
# 연도, 월, 일, 요일 파생변수 생성
df["order_year"] = df["Order Date"].dt.year
df["order_month"] = df["Order Date"].dt.month
df["order_day"] = df["Order Date"].dt.day
df["order_dow"] = df["Order Date"].dt.dayofweek
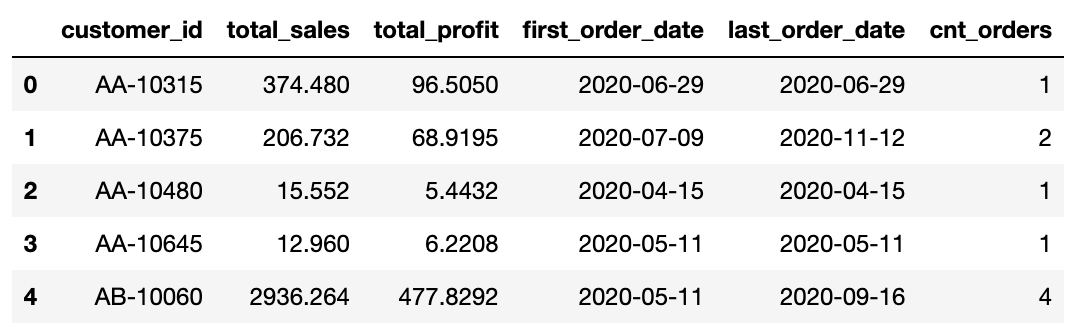
6. 고객에 대한 데이터셋 정의
df(raw data)는 한 장바구니에 대한 데이터라도 물품별 주문건수를 행으로 기입된 것이다. 고객별로 주문건수가 어떻게 되는지, 총 지출정도가 어떻게 되는지 등을 새로운 데이터프레임으로 정의한다.
# 고객별 총 판매액, 순이익, 첫구매일, 최근구매일, 구매횟수를 customer_df에 저장한다.
customer_df = df.groupby(by='Customer ID').agg({'Sales': 'sum',
'Profit': 'sum',
'Order Date': ['min', 'max'],
'Order ID': 'nunique'})
# 인덱스에 위치한 사용자 id를 컬럼으로 내보낸다.
customer_df.reset_index(inplace=True)
# 컬럼명을 다시 정의한다.
columns = ['customer_id', 'total_sales', 'total_profit','first_order_date', 'last_order_date', 'cnt_orders']
customer_df.columns = columns
7. 주문건수와 구매자 수
7-1. 월별 주문건수와 구매자 수
# 월을 기준으로 그룹화하고 월별 주문건수, 구매자 수를 구한다.
g_df = df.groupby('order_month').agg({"Customer ID": "nunique", "Order ID": "nunique"})
# 주문건수는 bar, 구매자 수는 line으로 그래프를 그린다.
fig, ax = plt.subplots(figsize=(8, 4))
colors = sns.color_palette('Blues', 12)
plt.bar(g_df.index, g_df['Order ID'], color=colors, label='주문수')
plt.plot(g_df.index, g_df['Customer ID'], color='k',
linestyle='--', marker='o', label='고객수')
plt.legend(ncols=1)
plt.show()
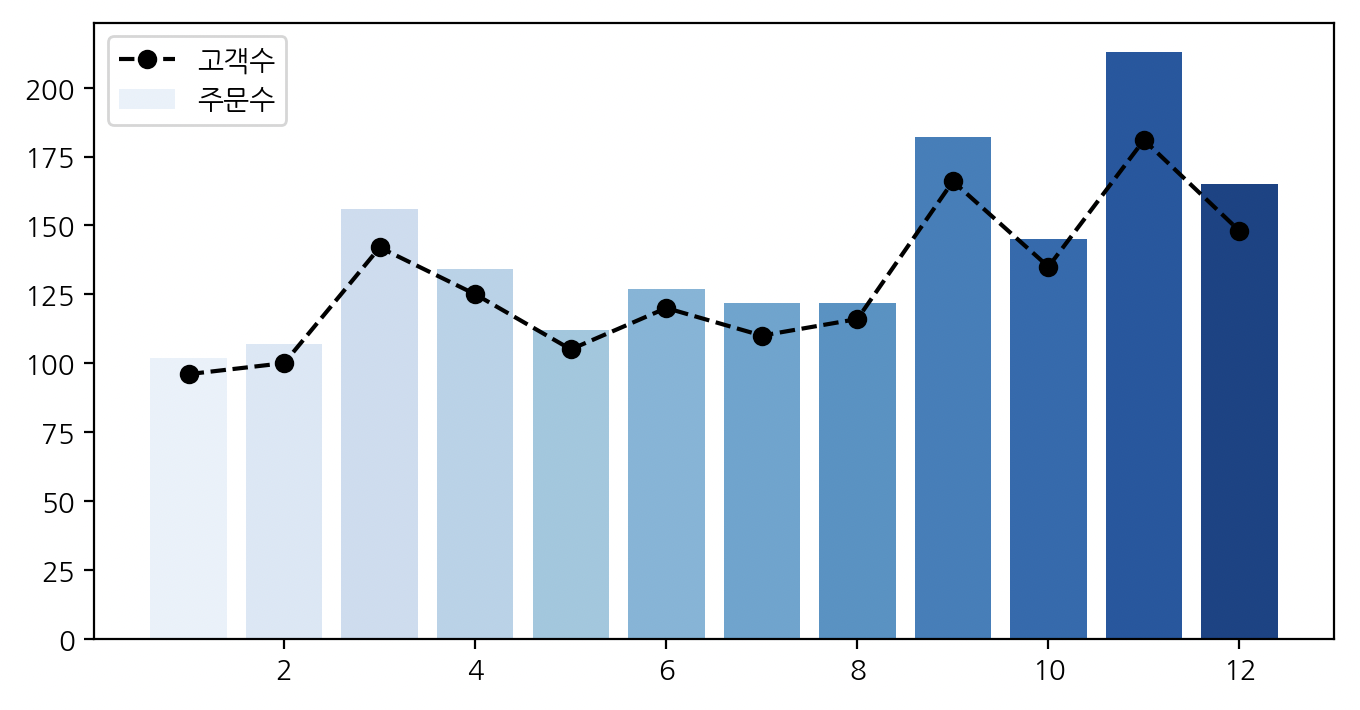
위 그래프를 보면 알 수 있듯이, 한 고객이 해당 월에 두번 이상 구매하는 경우는 잘 없다. 라인그래프와 바 그래프의 위치가 거의 동일하다는 것은 한 고객이 특정 월에 물품을 구매할 때, 그 월에 한번 더 구매하는 경우는 잘 일어나지 않는다는 뜻이다. 해당 그래프를 보니 RFM 분석을 한다면 R를 '최근 한달 내에 구매했는가?'를 기준으로 분석해봐야겠다고 생각이 들었다.
7-2. 요일별 주문건수와 구매자 수
# 요일을 기준으로 그룹화하고 요일별 주문건수, 구매자 수를 구한다.
g_df = df.groupby('order_dow').agg({"Customer ID": "nunique", "Order ID": "nunique"})
g_df.index = [w for w in '월화수목금토일']
# 주문건수는 bar, 구매자 수는 line으로 그래프를 그린다.
fig, ax = plt.subplots(figsize=(8, 4))
colors = sns.color_palette('Blues', 12)
plt.bar(g_df.index, g_df['Order ID'], color=colors, label='주문수')
plt.plot(g_df.index, g_df['Customer ID'], color='k',
linestyle='--', marker='o', label='고객수')
plt.legend(ncols=1)
plt.show()
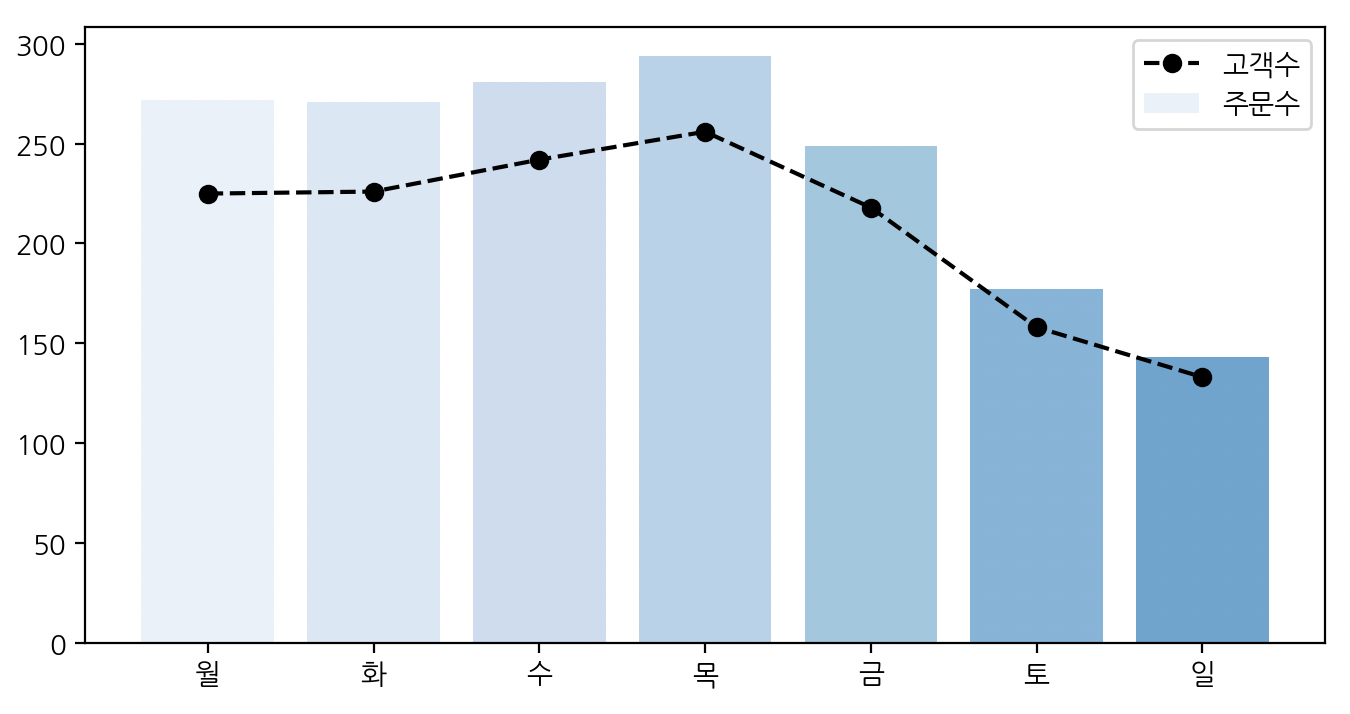
주로 사무실에서 사용하는 물품을 판매하다 보니 평일에 주문이 많이 이루어지는 것을 알 수 있다.
8. 판매액과 순이익
월별, 요일별 총 판매액과 순이익에 대한 그래프를 그려본다. 두 변수에 대한 관계를 시각화를 통해 예측해 본다.
8-1. 월별 판매액과 순이익
# 월별 총 판매액, 판매한 총 물품 수량, 순이익
g_df = df.groupby(by='order_month').agg({'Sales': 'sum', 'Quantity': 'sum', 'Profit': 'sum'})
g_df.reset_index(inplace=True)
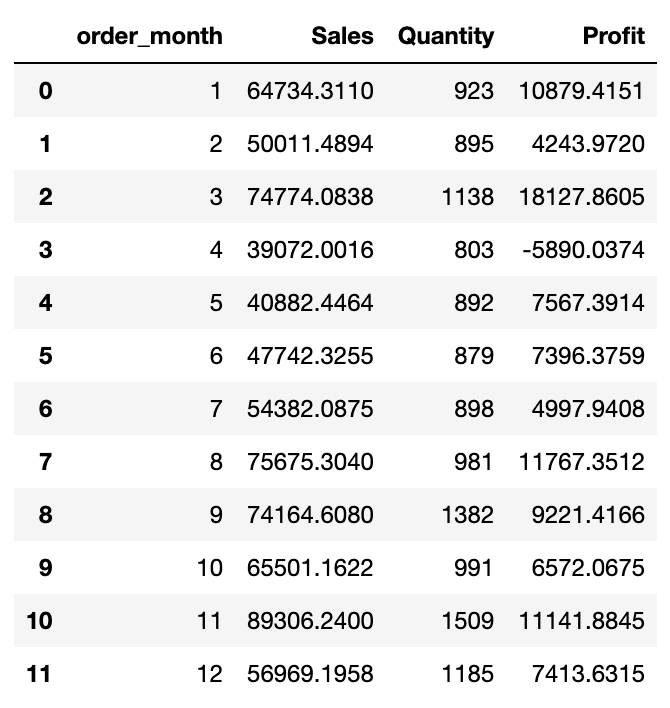
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot()
# 첫 번째: 바 차트(월별 총 판매액)
colors = sns.color_palette('Blues', 12)
ax1.set_xticks(g_df.index)
ax1.bar(g_df.index, g_df['Sales'], color=colors, label='판매액')
ax1.set_xlabel('월')
ax1.set_ylabel('판매액')
ax1.legend(loc='upper right', frameon=False)
# 두 번째: 라인 차트(월별 총 순이익)
color = 'k'
ax2 = ax1.twinx()
ax2.plot(g_df.index, g_df['Profit'], color=color, linestyle='--', marker='o', label='순이익')
ax2.set_ylabel('순이익', color='k')
ax2.legend(loc='upper right', bbox_to_anchor=(1.0, 0.9), frameon=False)
plt.show()
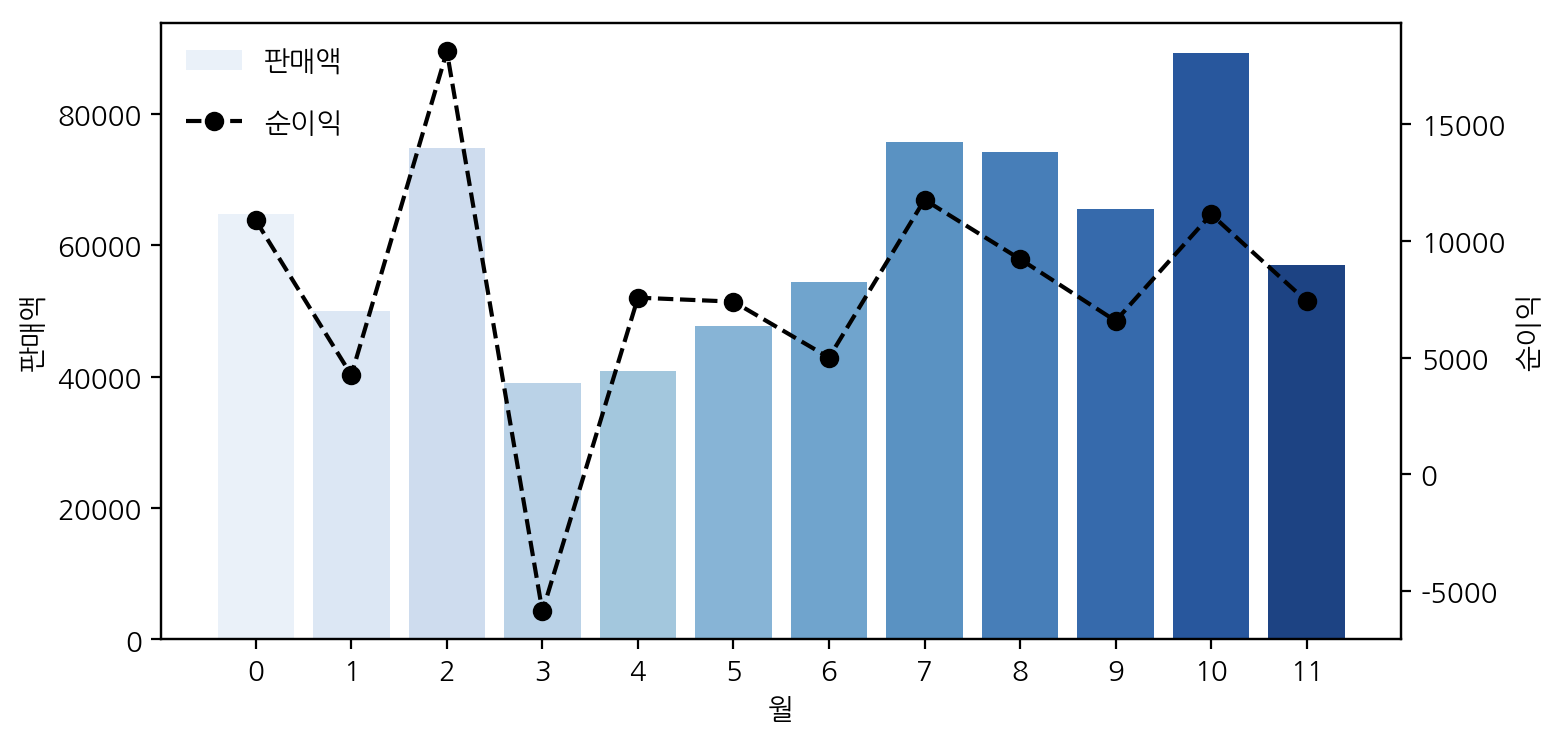
월별로 판매액과 순이익을 보면, 3월에 순이익이 -로 급격하게 라인그래프가 떨어지는 것을 알 수 있다. 판매액과 순이익의 그래프 경향이 비슷하긴 하지만(판매액이 상승하면 순이익이 상승, 판매액이 감소하면 순이익이 감소하는 경향), 특히 3월에 그래프에 급격한 변화가 있다. 3월에 무슨 일이 있었던 건지 조금 더 분석을 진행해봐야할 것같다.
8-2. 요일별 판매액과 순이익
# 요일별 총 판매액, 판매한 총 물품 수량, 순이익
g_df = df.groupby(by='order_dow').agg({'Sales': 'sum', 'Quantity': 'sum', 'Profit': 'sum'})
g_df.index = [w for w in '월화수목금토일']
g_df.reset_index(inplace=True)
g_df.columns = ['dow', 'Sales', 'Quantity', 'Profit']
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot()
# 첫 번째: 바 차트(월별 총 판매액)
colors = sns.color_palette('Blues', 12)
ax1.bar(g_df['dow'], g_df['Sales'], color=colors, label='판매액')
ax1.set_xlabel('요일')
ax1.set_ylabel('판매액')
ax1.legend(loc='upper right', frameon=False)
# 두 번째: 라인 차트(월별 총 순이익)
color = 'k'
ax2 = ax1.twinx()
ax2.plot(g_df['dow'], g_df['Profit'], color=color, linestyle='--', marker='o', label='순이익')
ax2.set_ylabel('순이익', color='k')
ax2.legend(loc='upper right', bbox_to_anchor=(1.0, 0.9), frameon=False)
plt.show()
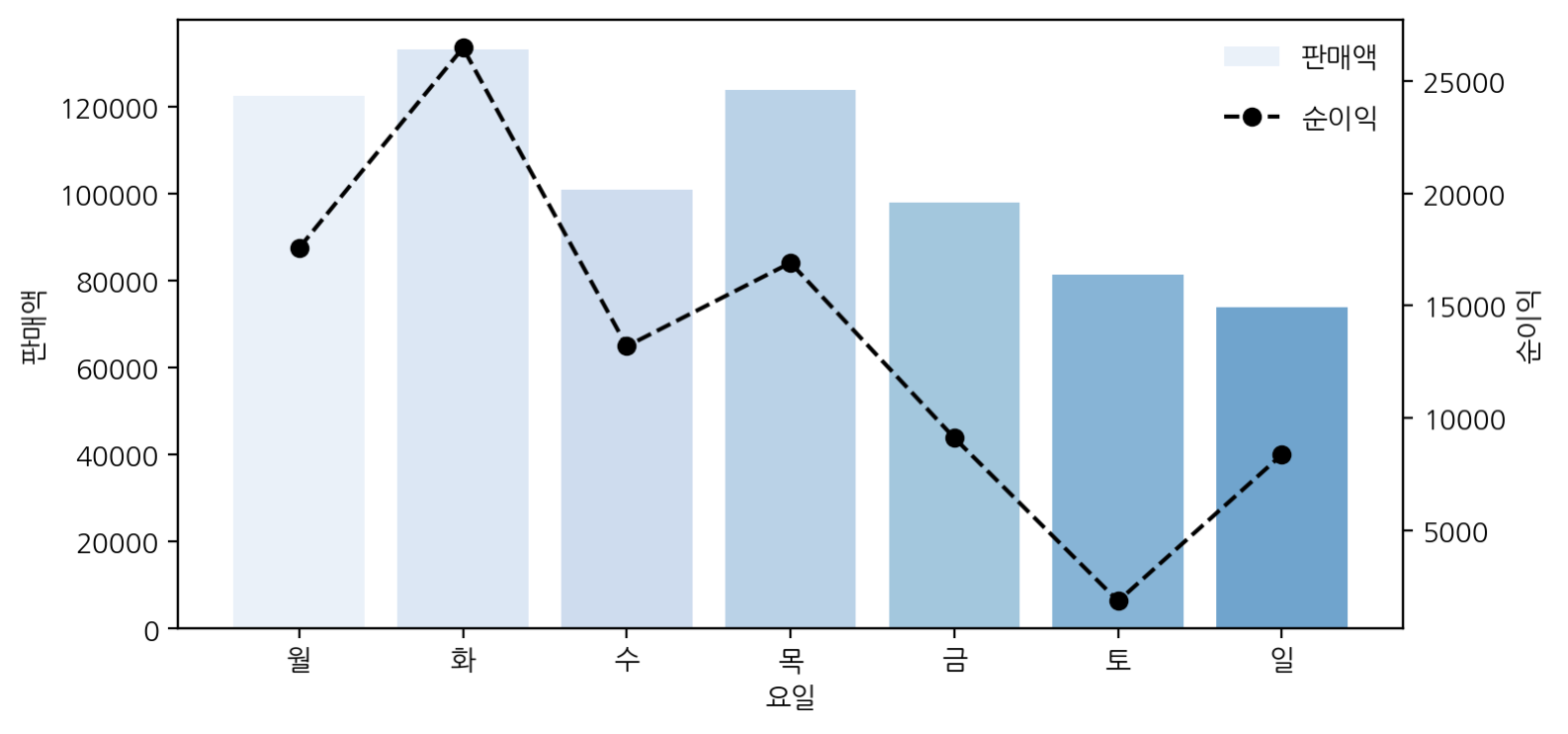
평일 중 ‘화요일’이 판매액이 가장 높고 순이익도 가장 높다. 요일별 판매액/순이익 그래프를 보면 경향이 비슷하다는 것을 알 수 있다. 판매액이 증가하면 순이익이 증가하고, 판매액이 감소하면 순이익도 감소하는 경향이다. 주말 중 ‘토요일’에 판매가 이루어지는 경우, 순이익이 거의 0에 가깝다. 왜 이런지 더 확인해봐야할 것같다. (토요일에 할인율이 많이 적용되는가? 결제시스템 문제인가? 결제 시스템에 대한 분석은 자료가 없어서 어렵다.)
9. 매출액 상위 품목과 국가
9-1. 판매량 상위 품목
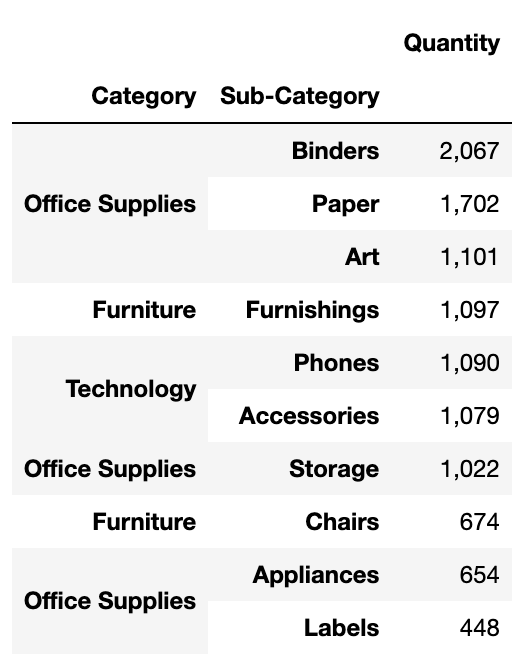
# 물품의 카테고리별 판매된 물품의 수를 기준으로 상위 10개 품목을 출력한다.
df.groupby(['Category', 'Sub-Category'])[['Quantity']].agg('sum').nlargest(10, 'Quantity').style.format('{:,.0f}')
9-2. 매출액 상위 품목
# 물품의 카테고리별 총 매출액을 기준으로 상위 10개 품목을 출력한다.
df.groupby(['Category', 'Sub-Category'])[['Sales']].agg('sum').nlargest(10, 'Sales').style.format('{:,.0f}')
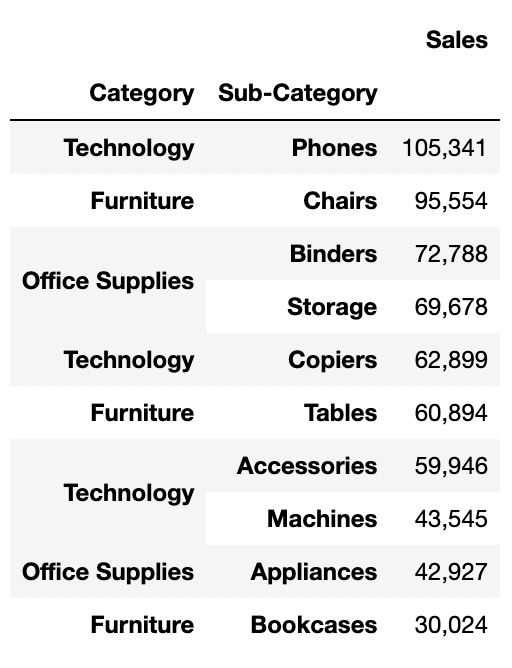
위 두 표를 보면 알 수 있듯이, 가장 많이 판매되는 품목은 바인더리, 종이와 같은 사무용품이다. Technology 중 Phone도 많이 팔리는 것을 알 수 있다. Phone은 카테고리별 판매된 물품의 수에서 5위를 차지했으나 단가가 높다는 점에서 가장 높은 매출을 나타내고 있다. 자사에선 사무실에서 필요한 저가의 소비재(사무용품)과 고가의 제품(가구, 전자제품)을 파는 곳임을 알 수 있다.
9-3. 매출액 상위 국가
# 주별 총 매출액을 기준으로 상위 10개의 state를 출력한다.
df.groupby('State')[['Sales']].agg('sum').nlargest(10, 'Sales').style.format('{:,.0f}')
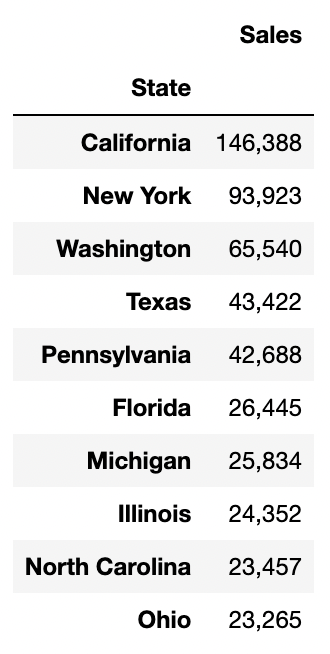
매출액이 가장 높은 주(state)는 캘리포니아이며 그 다음으로 높은 매출액을 보이는 곳은 뉴욕이다.
10. 순이익 상,하위 품목
# 카테고리별 총 순이익을 기준으로 상위 10개의 물품을 출력한다.
df.groupby(['Category', 'Sub-Category'])['Profit'].agg(['sum', 'mean']).nlargest(10, 'sum').style.format('{:,.0f}')
# 카테고리별 총 순이익을 기준으로 하위 10개의 물품을 출력한다.
df.groupby(['Category', 'Sub-Category'])['Profit'].agg(['sum', 'mean']).nsmallest(10, 'sum').style.format('{:,.0f}')
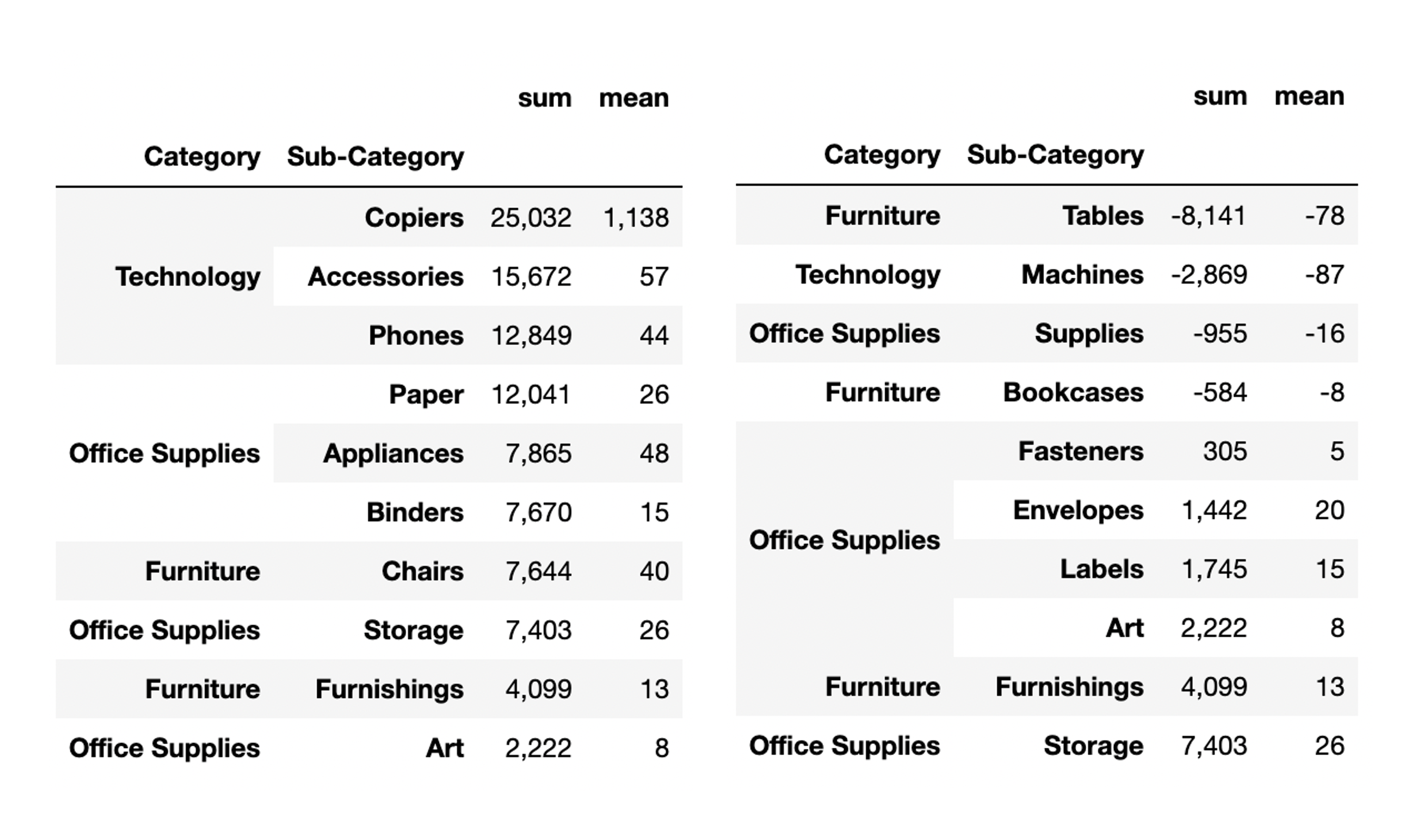
물품별 순이익을 확인해보면, Technology 중 복사기가 가장 높은 순이익을 나타내고 있다. 참고로 복사기는 판매량이 가장 작은 물품이다. 반대로 Furniture 중 테이블 항목의 물품에서 약 -8000 정도의 적자를 보고있다. 다음 비즈니스 분석에서 순이익이 -값을 나타내고 있는 항목들에 대한 개선 방향을 알아봐야겠다.
11. Reference
- Kaggle, ‘United States E-Commerce records 2020’ 데이터셋 출처
- bytetool, ASCII/Binary of 0xa0
- stackoverflow, ‘utf-8’ codec can’t decode byte 0xa0 in position 4276: invalid start byte
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기