
[비즈니스 분석] Python으로 US E-commerce 데이터 분석하기 - RFM
목표: Kaggle의 ‘United States E-Commerce records 2020’ 데이터셋으로 RFM 분석한다.
🚨 warning
‘주문일자’의 자료형 변경 과정에 이슈가 있어 RFM 분석을 통해 구한 그룹별 고객의 수는 잘못된 수치이다. 문제 발견 및 해결 과정은 ‘SQL로 미국 이커머스 데이터 분석하기’ 에 자세히 기록하였다.
프로젝트 목적
- ‘2020년 미국의 E-커머스 판매 데이터’ 유저의 구매 데이터를 기반으로 RFM 분석을 하고, 이를 바탕으로 인사이트와 액션을 제안해 본다.
🔍 RFM 분석이란?
CRM(Customer Relationship Management) 기법 중 하나로 아래 세 가지 유형을 기준으로 사용자 그룹을 나누어 분류하는 분석 기법이다.
Recency : 얼마나 최근에 구매했는가
Frequency : 얼마나 자주 구매했는가
Monetary : 얼마나 많은 금액을 지출했는가
1. 데이터, 라이브러리 로드
분석에 필요한 라이브러리를 로드한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 그래프 그릴 때, 한글지원
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'
Kaggle에서 다운받은 파일을 로드한다.
df = pd.read_csv('US_E_commerce_records_2020.csv', encoding='windows-1252')
📝 windows-1252
해당 파일을 로드하면 utf-8 방식으로 디코딩할 수 없고 위치가 8587의 바이트가 0xa0라는 에러 메세지가 발생한다. 확장된 ASCII 에 널리 사용되는 windons-1252를 사용하면 데이터를 불러올 수 있다. 자세한 해결 과정은 EDA 과정을 담은 게시물을 참고하면 된다.
2. 고객에 대한 데이터셋 정의
df(raw data)는 한 장바구니에 대한 데이터라도 물품별 주문건수를 행으로 기입된 것이다. 고객별로 주문건수가 어떻게 되는지, 총 지출정도가 어떻게 되는지 등을 새로운 데이터프레임으로 정의한다.
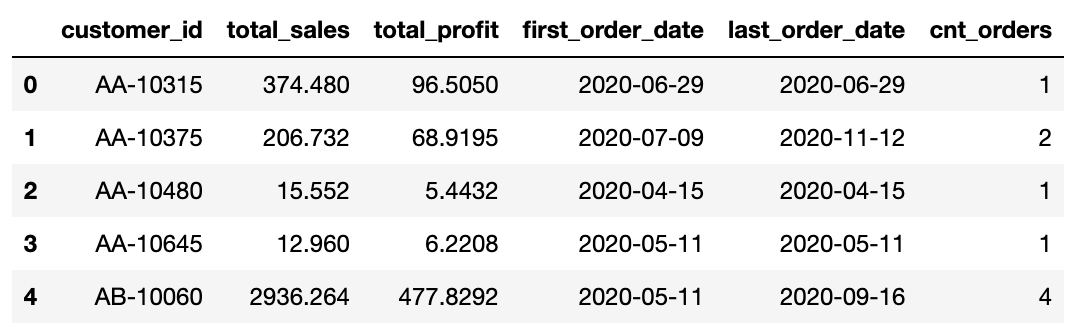
# 고객별 총 판매액, 순이익, 첫구매일, 최근구매일, 구매횟수를 customer_df에 저장한다.
customer_df = df.groupby(by='Customer ID').agg({'Sales': 'sum',
'Profit': 'sum',
'Order Date': ['min', 'max'],
'Order ID': 'nunique'})
# 인덱스에 위치한 사용자 id를 컬럼으로 내보낸다.
customer_df.reset_index(inplace=True)
# 컬럼명을 다시 정의한다.
columns = ['customer_id', 'total_sales', 'total_profit','first_order_date', 'last_order_date', 'cnt_orders']
customer_df.columns = columns
3. RFM 기준 선정
RFM 분석을 진행하기 전, 세 유형의 기준을 정했다. 기준은 아래와 같은 이유로 선정하였다. (모든 고객에 대하여 최근성, 행동 빈도, 구매 금액을 수치화할 수 있으나 간단하게 RFM 분석을 진행하는 것을 목표로 설정)
📍 기준에 적합한 데이터는 1로 표시하고 맞지 않는 데이터는 0으로 표시한다.
3-1. Recency
# 월을 기준으로 그룹화하고 월별 주문건수, 구매자 수를 구한다.
g_df = df.groupby('order_month').agg({"Customer ID": "nunique", "Order ID": "nunique"})
# 주문건수는 bar, 구매자 수는 line으로 그래프를 그린다.
fig, ax = plt.subplots(figsize=(8, 4))
colors = sns.color_palette('Blues', 12)
plt.bar(g_df.index, g_df['Order ID'], color=colors, label='주문수')
plt.plot(g_df.index, g_df['Customer ID'], color='k',
linestyle='--', marker='o', label='고객수')
plt.legend(ncols=1)
plt.show()
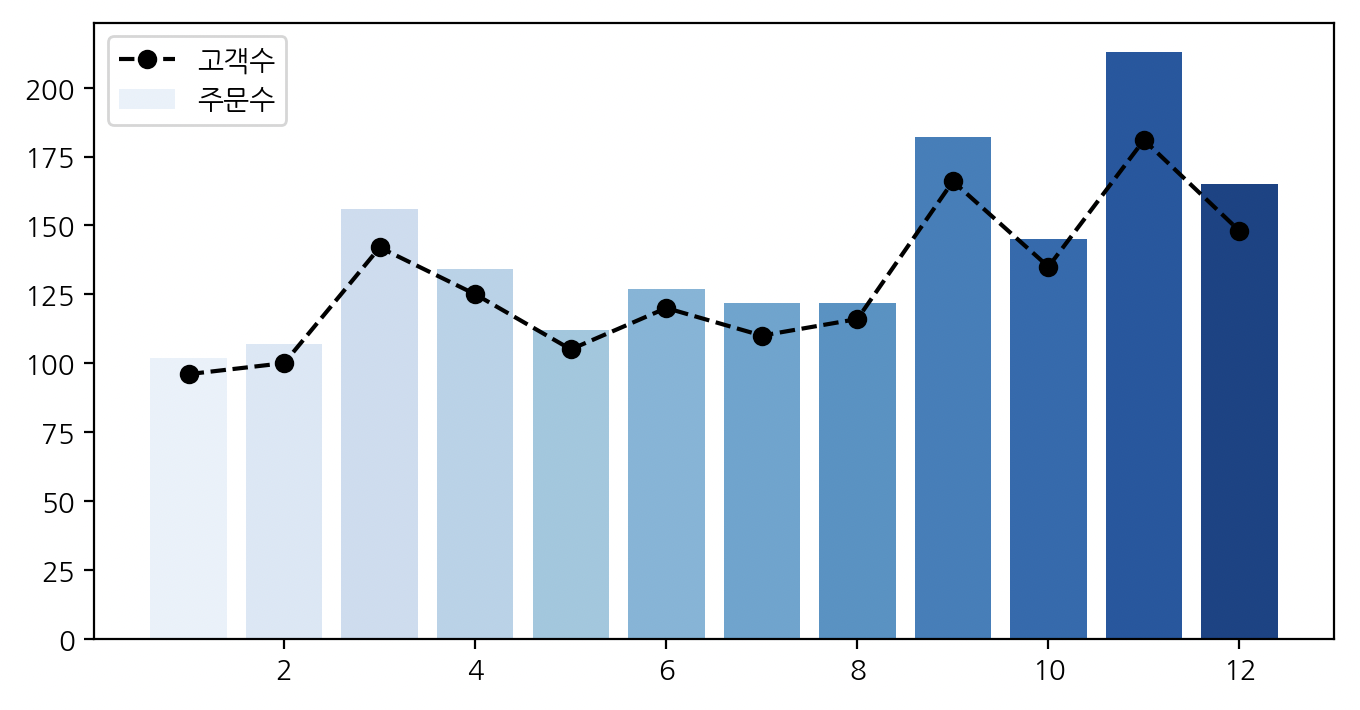
위 그래프를 보면 알 수 있듯이, 한 고객이 해당 월에 두 번 이상 구매하는 경우는 잘 없다(월별로 구매한 고객의 nunique값과 주문건수의 값이 거의 일치). 그래프를 보니, 사무실에서 필요한 물품을 구매하는데 한달에 한 번 이상 구매한다면 자사에 어느정도 충성도가 있지않을까라는 생각이 들었다. 이러한 이유로 R를 '최근 한달 내에 구매했는가?'를 기준으로 설정했다. 2020년도 판매 내역의 데이터이므로 최근 한달의 기준은 2021년 01월 01일을 기준으로 설정한다.
📝 Recency 기준
2021년 1월 1일 기준, 최근 한달 내에 구매 이력이 있는가?
3-2. Frequency
# 고객별 주문횟수의 분포를 확인하기 위해 boxplot 그린다.
fig, ax = plt.subplots(figsize=(5, 3))
sns.boxplot(data=customer_df, x='cnt_orders', color='lightblue')
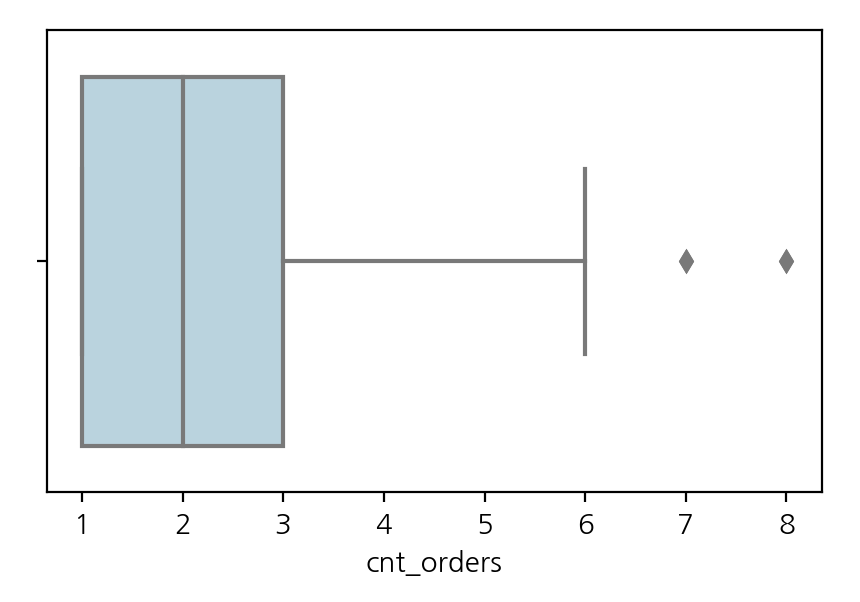
# 고객별의 90%가 4번이하의 주문 경험이 있다.
customer_df['cnt_orders'].quantile(.90)
>>> 4.0
F는 ‘5번 이상의 구매경험이 있는가?’를 기준으로 설정하였다. 고객별 주문횟수의 boxplot 그래프와 고객의 90%가 4번 이하의 주문경험이 있다는 점에서 착안하였다. 상위 10% 이내의 고객의 구매경험을 기준으로 하면 자사에 대한 애정 정도를 분류하는데 도움이 될 것이라고 판단하였다.
📝 Frequency 기준
5번 이상의 구매경험이 있는가?
3-3. Monetary
# 고객별 판매액의 분포를 확인하기 위해 boxplot 그린다.
sns.boxplot(x=customer_df['total_sales'], color='lightblue')
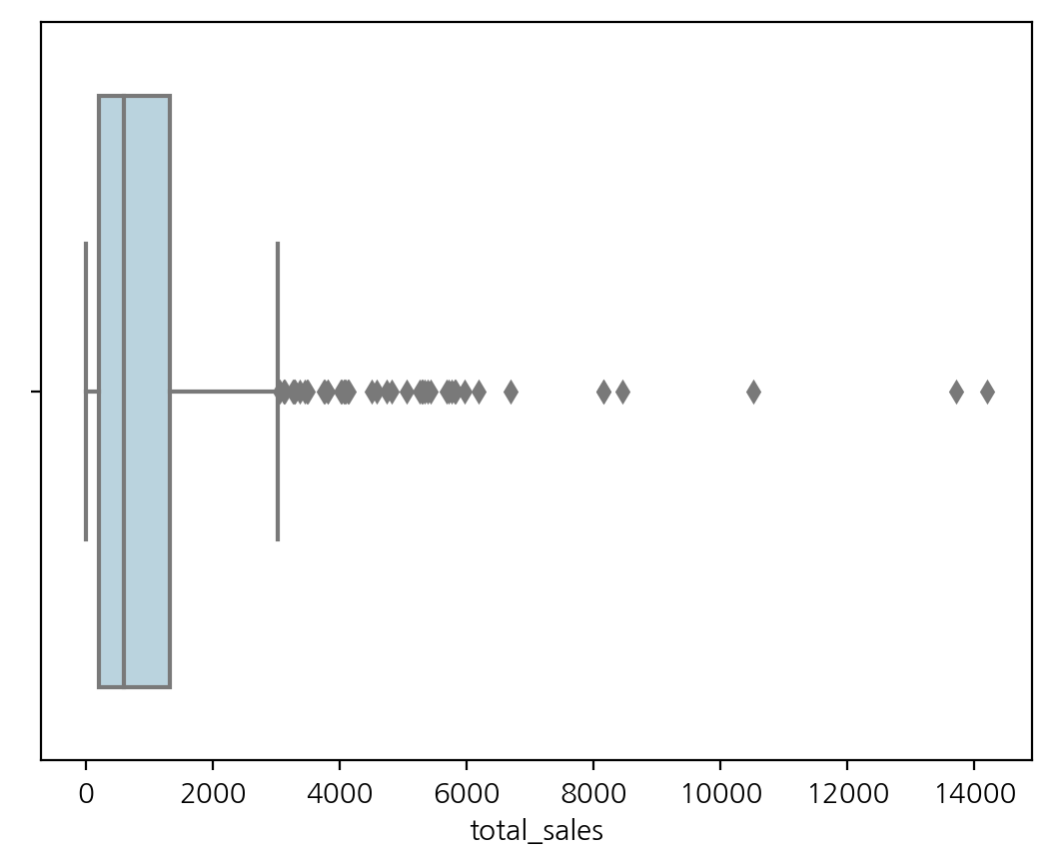
# 고객별의 90%가 약 2384 달러 이하의 지출경험이 있다.
customer_df['total_sales'].quantile(0.90)
>>> 2384.610400000001
M는 ‘2500 달러 이상의 지출경험이 있는가?’를 기준으로 설정하였다. 고객별 총 지출금액의 boxplot 그래프와 고객의 90%가 약 2384 달러 이하의 지출경험이 있다는 점에서 착안하였다. 상위 10% 이내의 고객의 구매경험을 기준으로 하면 자사에 대한 애정 정도를 분류하는데 도움이 될 것이라고 판단하였다.
📝 Monetary 기준
2500 달러 이상의 지출경험이 있는가?
4. RFM Segmentation
# r, f, m 값 구하기
customer_df.loc[customer_df['last_order_date'] >= '2020-12-01', 'recency'] = 1
customer_df.loc[customer_df['cnt_orders'] >= 5, 'frequency'] = 1
customer_df.loc[customer_df['total_sales'] >= 2500, 'monetary'] = 1
customer_df.fillna(0, inplace=True)
# 고객별 r, f, m 값을 rfm 변수에 저장하기
rfm = customer_df[['customer_id', 'recency', 'frequency', 'monetary']].copy()
# 소수점이 아닌 정수로 저장하기
rfm['recency'] = rfm['recency'].astype(int)
rfm['frequency'] = rfm['frequency'].astype(int)
rfm['monetary'] = rfm['monetary'].astype(int)

rfm.groupby(['recency', 'frequency', 'monetary'])[['customer_id']].agg('count')

5. 결론
결과를 해석해 보면, recency가 1인 경우는 최근에 구매가 이루어진 것이고 0은 구매가 뜸해진 케이스를 의미한다. 이때 구매가 뜸해진 고객 중, 우리 서비스를 다시 이용할 것같은 사람에게 할인쿠폰을 전달하거나 고객에게 적합한 물건을 푸시하는 등의 시도를 해야한다. 구매가 뜸해진 고객(recency가 0) 중 구매경험과 지출금액이 많은 고객(frequency와 monetary 가 1)에게 1차로 쿠폰을 제공한다.(재구매 확률이 높음) 만약 최근 구매가 뜸해졌으나 구매경험은 많고 지출금액이 적은 고객(recency 1, frequency 1, monetary 0)은 저가의 상품에 관심이 많은 경우일 수 있다는 점에서 쿠폰을 지급하되 특정 조건에서 적용할 수 있도록 한다.(예를 들어 3만원 이상 구매 시, 할인쿠폰 적용가능 or 배송비 무료) 추가로 rfm이 001인 경우(최근구매x, 구매경험 적음, 지출금액 높음)은 자사에서 판매하는 물품 중 고가의 제품(예를 들어 Technology)을 구매했을 가능성이 높다. 고가의 제품은 타사와 비교해서 구매했을 가능성이 높다. 유저가 특정 제품을 클릭하는 시간대를 파악하여 쿠폰을 발급하는 것은 어떨까? ‘고객님께만 드리는 깜짝 할인쿠폰, 유효기간 n시간..’ 사용이 가능한 시간을 작게 설정하여 구매를 유도하는 것은 어떨까 하는 생각이 들었다.
RFM 분석 이전에 설정한 기준을 바탕으로 분석한 결과, 자사에 대한 VIP 고객은 20명 내외인 것으로 보인다.(111, 110) 특히 자사에서 판매중인 물품이 사무실을 타겟팅으로 했다는 점에서 000인(다시 재구매할 가능성이 낮음)이 477명이다. 100(최근에 구매했으나 구매경험이 적음) 유형의 고객도 115명이라는 점에서 자사의 이익을 높이려면 상품의 영역을 넓히는 것이 중요하다고 판단된다. 사무용품은 필요할 때 대량으로 구매하고 떨어질 때쯤 다시 구비하는 경향이 있기 때문이다.
cf. 110을 VIP 고객으로 분류한 이유는 자사의 판매 물품 카테고리를 보면 사무용품(저가 소비재)가 대부분이라는 점에서 지출금액은 적어도 빈번히 물품을 구매하는 고객 유형을 포함시켰다.
6. 마치며
이번 프로젝트로 US E-커머스의 데이터로 간단한 RFM 분석을 진행해 보았다. 데이터에 대해 아쉬운 점은 결제 시스템, 고객의 리뷰(별점이나 코멘트), 배송지역별 배송비 등에 대한 정보가 없다는 것이다. RFM 분석 결과를 바탕으로 그룹별로 어떤 요소에 민감하게 반응하는지 등을 알아볼 수 있었다면 더 재밌게 프로젝트를 진행했을 것같다. 다음엔 RFM 값을 매길 때 정해둔 기준 없이 있는 데이터 그대로를 사용해서 RFM 값을 수치화하고 구간으로 나누어서 진행해 보아야겠다!
7. Reference
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기