
[비즈니스 분석] SQL로 US E-commerce 데이터 분석하기 - RFM
목표: Kaggle의 ‘United States E-Commerce records 2020’ 데이터셋으로 RFM 분석한다.
1. RFM 분석
Kaggle에서 다운받은 데이터를 빅쿼리(BigQuery)에 추가하여 RFM 분석을 진행하였다. 데이터세트를 test, 테이블을 us_e_commerce 로 설정하였다.
cf. 테이블을 불러오려면 ‘데이터세트명.테이블명’ 형태인 ‘test.us_e_commerce’ 로 불러와야한다.
1-1. RFM 기준
RFM 분석을 진행하기 전, 세 유형의 기준을 정했다. 기준은 아래와 같으며 이유는 ‘Python으로 RFM 분석하기’에 기록되어있다. (모든 고객에 대하여 최근성, 행동 빈도, 구매 금액을 수치화할 수 있으나 간단하게 RFM 분석을 진행하는 것을 목표로 설정)
Recency: 2021년 1월 1일 기준, 최근 한달 내에 구매 이력이 있는가?
Frequency: 5번 이상의 구매경험이 있는가?
Monetary: 2500 달러 이상의 지출경험이 있는가?
1-2. RFM 점수 부여
SELECT customer_id
, last_order_date
, cnt_orders
, sum_sales
, IF(last_order_date >= '2020-12-01', 1, 0) AS recency
, IF(cnt_orders >= 5, 1, 0) AS frequency
, IF(sum_sales >= 2500, 1, 0) AS monetary
FROM (SELECT customer_id
, MAX(order_date) AS last_order_date
, COUNT(DISTINCT order_id) AS cnt_orders
, SUM(sales) AS sum_sales
FROM test.us_e_commerce
GROUP BY customer_id) AS customers
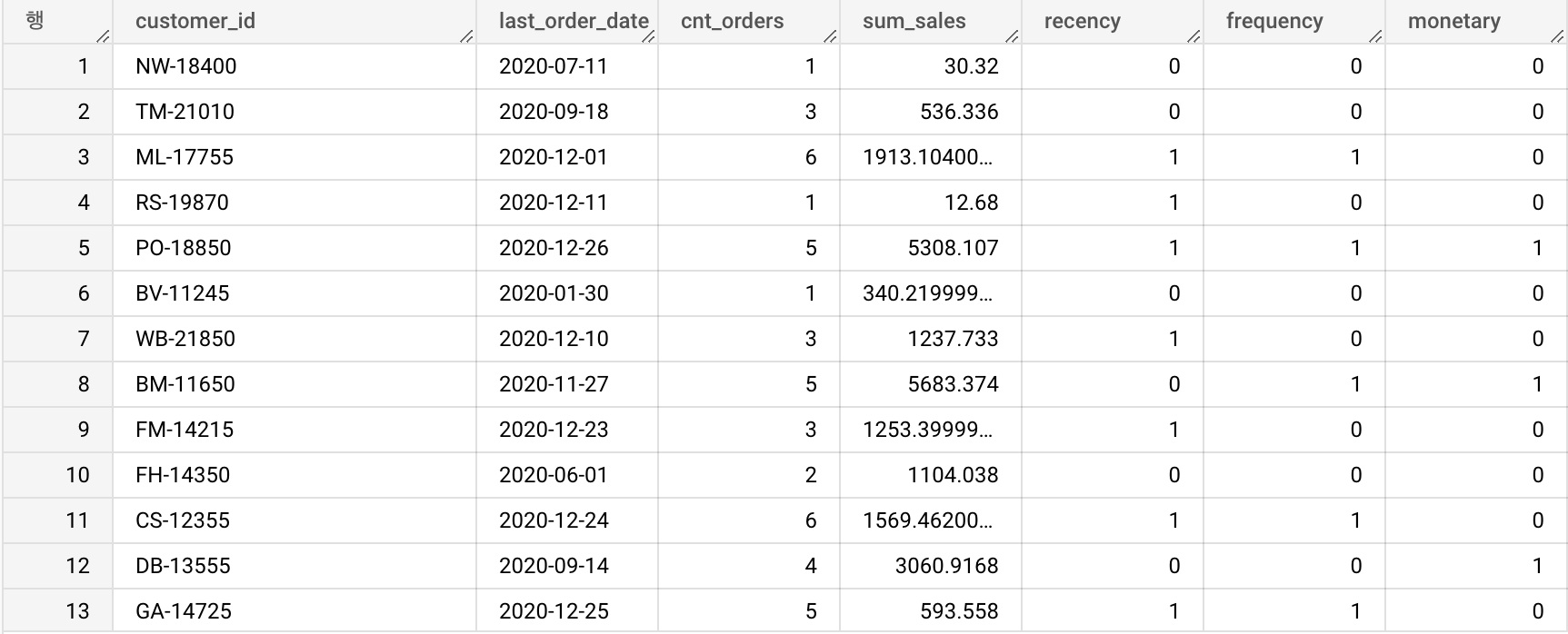
1-3. RFM 그룹별 고객의 수
SELECT IF(last_order_date >= '2020-12-01', 1, 0) AS recency
, IF(cnt_orders >= 5, 1, 0) AS frequency
, IF(sum_sales >= 2500, 1, 0) AS monetary
, COUNT(customer_id) AS num_customers
FROM (SELECT customer_id
, MAX(order_date) AS last_order_date
, COUNT(DISTINCT order_id) AS cnt_orders
, SUM(sales) AS sum_sales
FROM test.us_e_commerce
GROUP BY customer_id) AS customers
GROUP BY recency, frequency, monetary
ORDER BY recency, frequency, monetary
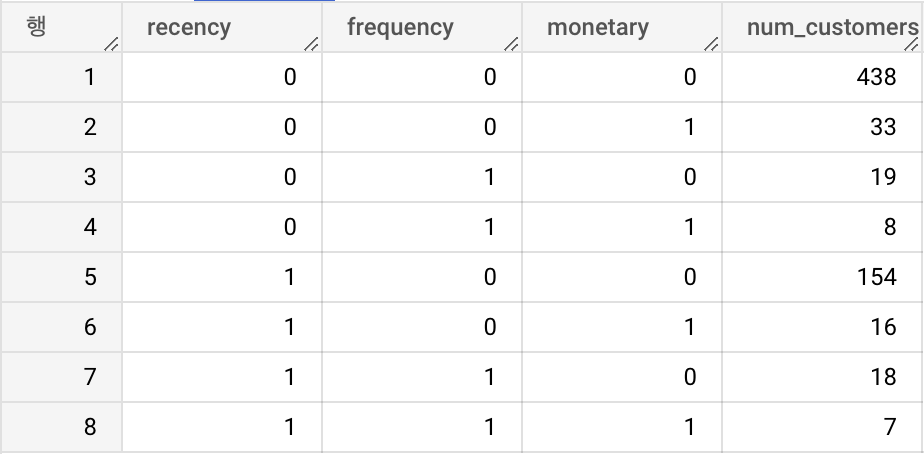
RFM 분석결과 타입별 고객의 수를 출력해보았다. 조금 더 알아보기 쉽게 R, F, M을 기준으로 정렬해보았다.
🌞 문제 발견 with 파이썬
Python과 SQL로 RFM을 도출해낸 결과를 보면 그룹별 고객의 수가 다른 것을 알 수 있다. 아래 이미지는 Python과 SQL에서 구한 RFM로 구한 그룹별 고객의 수이다.
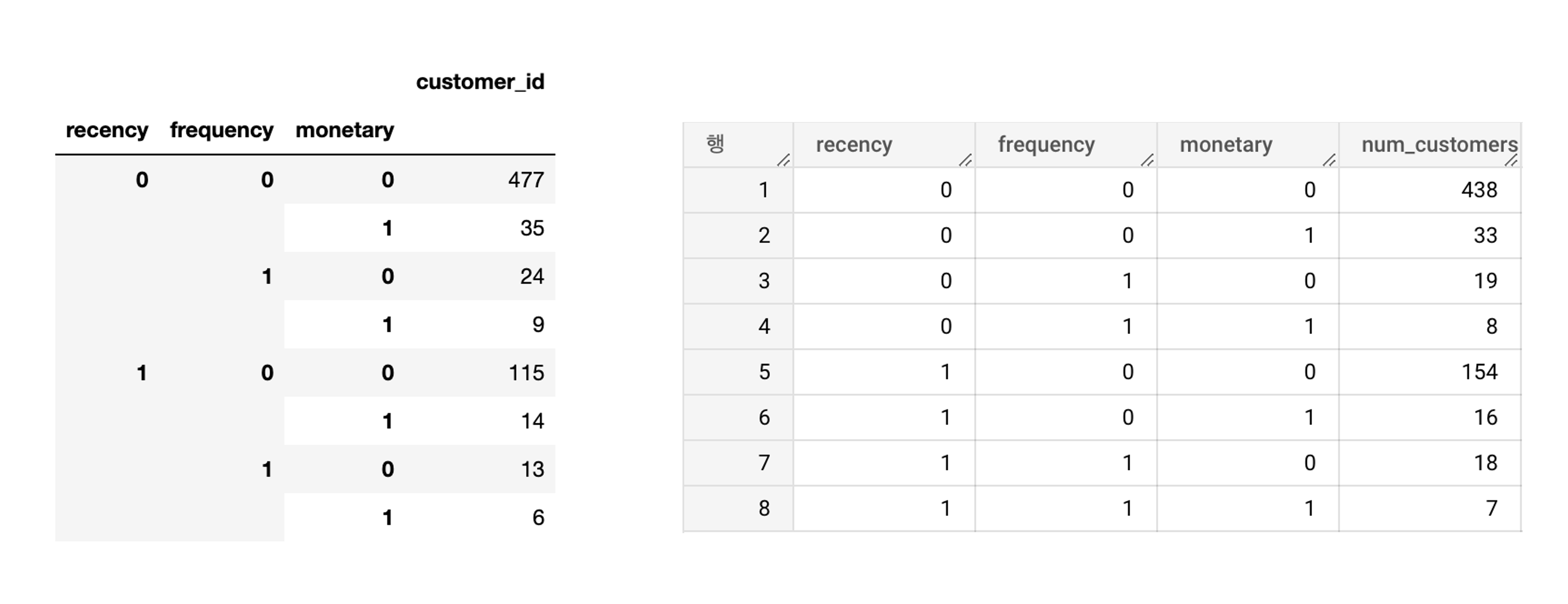
000에 해당하는 고객 수를 비교하면 Python으로 구한 경우 477명, SQL로 구한 경우는 438로 39명이 차이난다. 이런 차이가 나는 이유를 찾다가 SQL에서의 코드는 문제가 없는 것으로 판단되었다. 코드 결과를 보다가 csv 파일을 빅쿼리에 로드하는 과정에서 ‘일-월-연도’ 형태의 주문일자가 자동으로 ‘연도-월-일’ 구조의 날짜타입으로 생성이 되었는데 이 과정에서 문제가 일어난 것인지 확인해 보았다. 원본 데이터와 빅쿼리에 로드된 데이터의 날짜를 비교해보니 잘 변경되었음을 확인할 수 있었다. Python에서 문자열 타입의 주문일자가 to_datetime 함수를 이용하여 날짜 타입으로 바꾸는 과정에서 문제가 발생된 것일 수 있다고 생각되었다. 주피터노트북으로 원본 데이터와 날짜 타입으로 변경한 데이터를 비교해 보았다.
📍 주문일자 변경X
# 원본 데이터(결과는 아래 이미지에서 왼쪽)
df = pd.read_csv('US_E_commerce_records_2020.csv', encoding='windows-1252')
# 고객별 총 지출액, 최초구매일, 마지막구매일, 총주문건수
df.groupby(by='Customer ID').agg({'Sales': 'sum',
'Order Date': ['min', 'max'],
'Order ID': 'nunique'})
📍 주문일자 변경O
# 주문일자의 자료형을 datetime로 변경(결과는 아래 이미지에서 오른쪽)
df = pd.read_csv('US_E_commerce_records_2020.csv', encoding='windows-1252')
# 주문일자가 담긴 컬럼을 to_datetime으로 날짜형으로 변경
df['Order Date'] = pd.to_datetime(df['Order Date'])
# 고객별 총 지출액, 최초구매일, 마지막구매일, 총주문건수
df.groupby(by='Customer ID').agg({'Sales': 'sum',
'Order Date': ['min', 'max'],
'Order ID': 'nunique'})
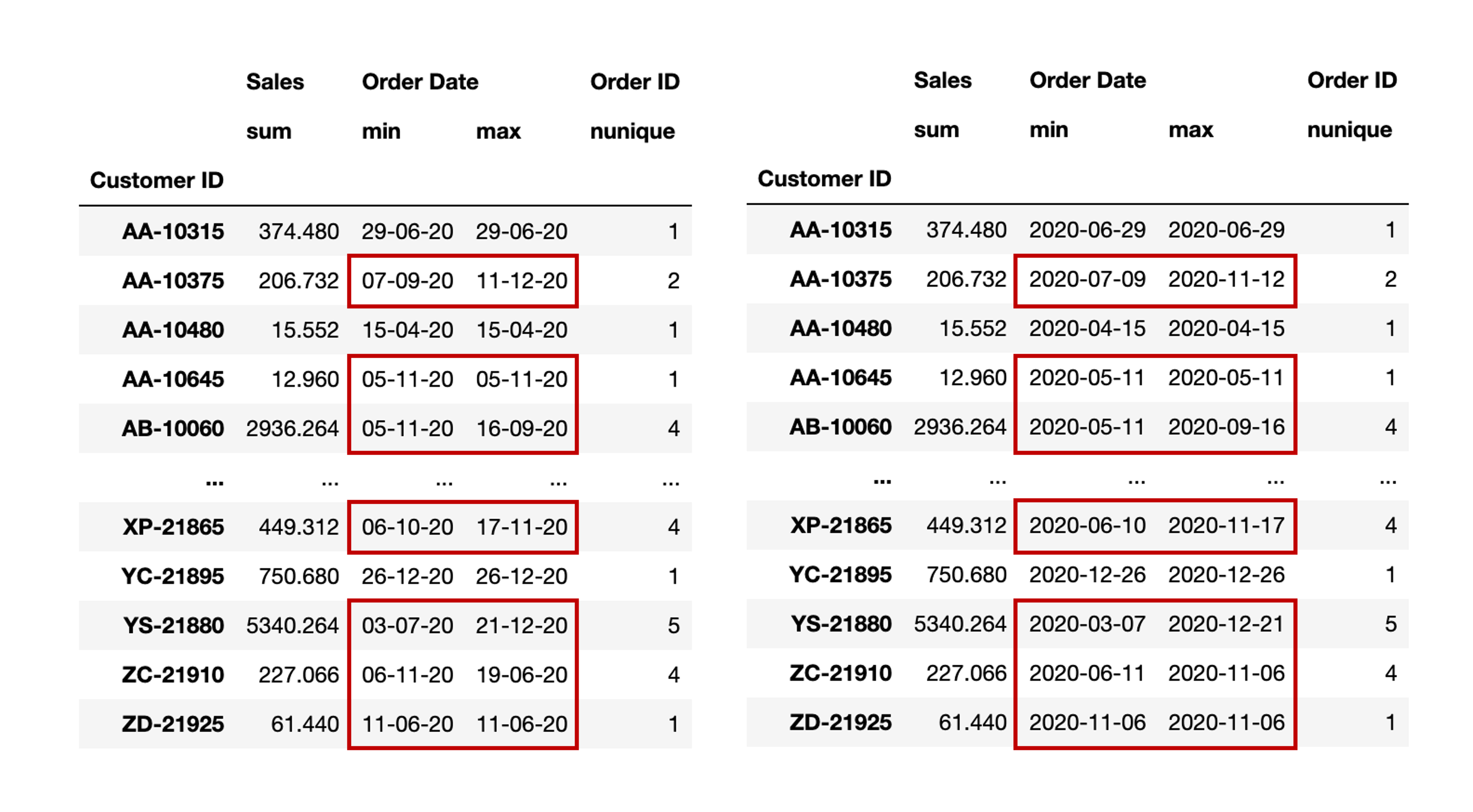
결과를 보면 ‘일-월-연도’로 이루어져있던 원본 데이터가 datetime으로 변경되는 과정에서 문제가 발생되었다는 것을 알 수 있다. ‘일-월-연도’에서 일자가 12보다 큰 경우는 일(day)로 잘 변경되었으나 일자가 12 이하인 경우는 월(month)로 변경되었다. 문제를 인식하고 다시 RFM를 분석해 보았다. 과정은 아래와 같다.
# 데이터 로드
df = pd.read_csv('US_E_commerce_records_2020.csv', encoding='windows-1252')
# 주문일자의 자료형을 변경하는 과정
# 연도는 2020년만 존재하기 때문에 일괄처리
df['order_year'] = '2020'
df['order_month'] = df['Order Date'].map(lambda x: x.split("-")[1])
df['order_day'] = df['Order Date'].map(lambda x: x.split("-")[0])
# '연도-월-일' 형태로 변경 후, datetime 형태로 변경
df['Order Date'] = df['order_year'] + '-' + df['order_month'] + '-' + df['order_day']
df['Order Date'] = pd.to_datetime(df['Order Date'])
# 고객별 총 지출액, 최초구매일, 마지막구매일, 총주문건수
customer_df = df.groupby(by='Customer ID').agg({'Sales': 'sum',
'Order Date': 'max',
'Order ID': 'nunique'})
# 인덱스에 위치한 사용자 id를 컬럼으로 내보냄
customer_df.reset_index(inplace=True)
# 컬럼명을 다시 정의
columns = ['customer_id', 'total_sales', 'last_order_date', 'cnt_orders']
customer_df.columns = columns
# R, F, M 수치화
customer_df.loc[customer_df['last_order_date'] >= '2020-12-01', 'recency'] = 1
customer_df.loc[customer_df['cnt_orders'] >= 5, 'frequency'] = 1
customer_df.loc[customer_df['total_sales'] >= 2500, 'monetary'] = 1
customer_df.fillna(0, inplace=True)
# 필요한 부분만 rfm 변수에 저장
rfm = customer_df[['customer_id', 'recency', 'frequency', 'monetary']].copy()
# RFM 수치화 후 그룹별 고객 수
rfm.groupby(['recency', 'frequency', 'monetary'])[['customer_id']].agg('count')

‘일-월-연도’ 형태의 주문일자를 ‘연도-월-일’ 형태로 바꾸고 날짜타입으로 변경한 후, RFM 분석을 다시 진행해 보았다. 결과는 SQL로 구한 결과와 동일하게 나왔다. 자료형을 변경하는 과정에서 이미 정의되어있는 함수를 사용하더라도 제대로 적용이 되었는지 확인하는게 중요하다는 것을 느꼈다.
1-4. 특정 그룹의 유저 리스트
만약 RFM 결과를 바탕으로 ‘011’ 로 분류된 유저에게 쿠폰을 보낸다면 쿠폰을 보낼 대상을 구해야한다. 쿠폰을 전송할 특정 유저들의 리스트를 구하는 방법은 다음과 같다.
🔍 구하는 과정 ver1
- 원본 데이터에서 고객을 기준으로 그룹화하고 고객별 최근구매일, 총구매액, 총주문건수를 서브쿼리로 불러온다.
- RFM이 011이 되는 경우를 조건식으로 만들어서 고객id만 출력한다.(R, F, M에 대한 수치화 과정 제외)
SELECT customer_id
FROM (SELECT customer_id
, MAX(order_date) AS last_order_date
, COUNT(DISTINCT order_id) AS cnt_orders
, SUM(sales) AS sum_sales
FROM test.us_e_commerce
GROUP BY customer_id) AS customers
WHERE last_order_date < '2020-12-01'
AND cnt_orders >= 5
AND sum_sales >= 2500
🔍 구하는 과정 ver2
- 원본 데이터에서 고객을 기준으로 그룹화하고 고객별 최근구매일, 총구매액, 총주문건수를 서브쿼리로 불러온다.
- R, F, M을 구하고 이 과정을 다시 새로운 서브쿼리로 생성하여 불러온다.
- R 0, F 1, M 1인 조건을 AND로 불러오고 그에 해당하는 고객 id를 출력한다.
SELECT customer_id
FROM (SELECT customer_id
, IF(last_order_date >= '2020-12-01', 1, 0) AS recency
, IF(cnt_orders >= 5, 1, 0) AS frequency
, IF(sum_sales >= 2500, 1, 0) AS monetary
FROM (SELECT customer_id
, MAX(order_date) AS last_order_date
, COUNT(DISTINCT order_id) AS cnt_orders
, SUM(sales) AS sum_sales
FROM test.us_e_commerce
GROUP BY customer_id) AS customers) AS rfm
WHERE recency = 0
AND frequency = 1
AND monetary = 1


서브쿼리를 두 번 만들었을 때(중첩), 사용한 슬롯 시간(SQL 쿼리를 실행하는 데 필요한 연산 능력의 단위) 20밀리초가 더 걸렸다. 서브쿼리는 실체적인 데이터를 가지지 않고 가상의 테이블을 만든다는 점에서 연산 비용이 추가된다.(일시적인 테이블) 지금은 약 3000행의 데이터를 사용했기에 큰 차이는 없지만 대량의 데이터를 처리한다면 두 방식의 실행속도에 차이가 분명할 것이다. 서브쿼리를 만들지 않아도 된다면 서브쿼리 생성없이 결과를 불러오는 것이 좋을 것같다.
2. Reference
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기