
[Python] Parquet를 활용해 디스크 공간(Storage) 절약하기
Parquet 으로 빅데이터 파일의 용량을 줄여 디스크 공간 절약하기
✔️ Apache Parquet 이란?
하둡(Hadoop)에서 컬럼방식으로 저장하는 저장 포맷을 의미한다.
효율적인 데이터 저장 및 검색을 위해 설계된 오픈소스이다.
복잡한 데이터를 대량으로 처리하기 위해 향상된 성능과 함께 효율적인 데이터 압축 및 인코딩 체계를 제공한다.
- Parquet 의 특징
- 열의 값은 물리적으로 인접한 메모리 위치에 저장된다.
- 열 단위 압축은 효율적이고 저장 공간을 절약한다.
- 열 값이 동일한 데이터 타입이기 때문에 압축에 유리하다.
- 특정 열 값을 가져오는 쿼리는 전체 행 데이터를 읽을 필요가 없으므로 성능이 향상된다.
- 각 열에 다른 인코딩 기술을 적용할 수 있다.
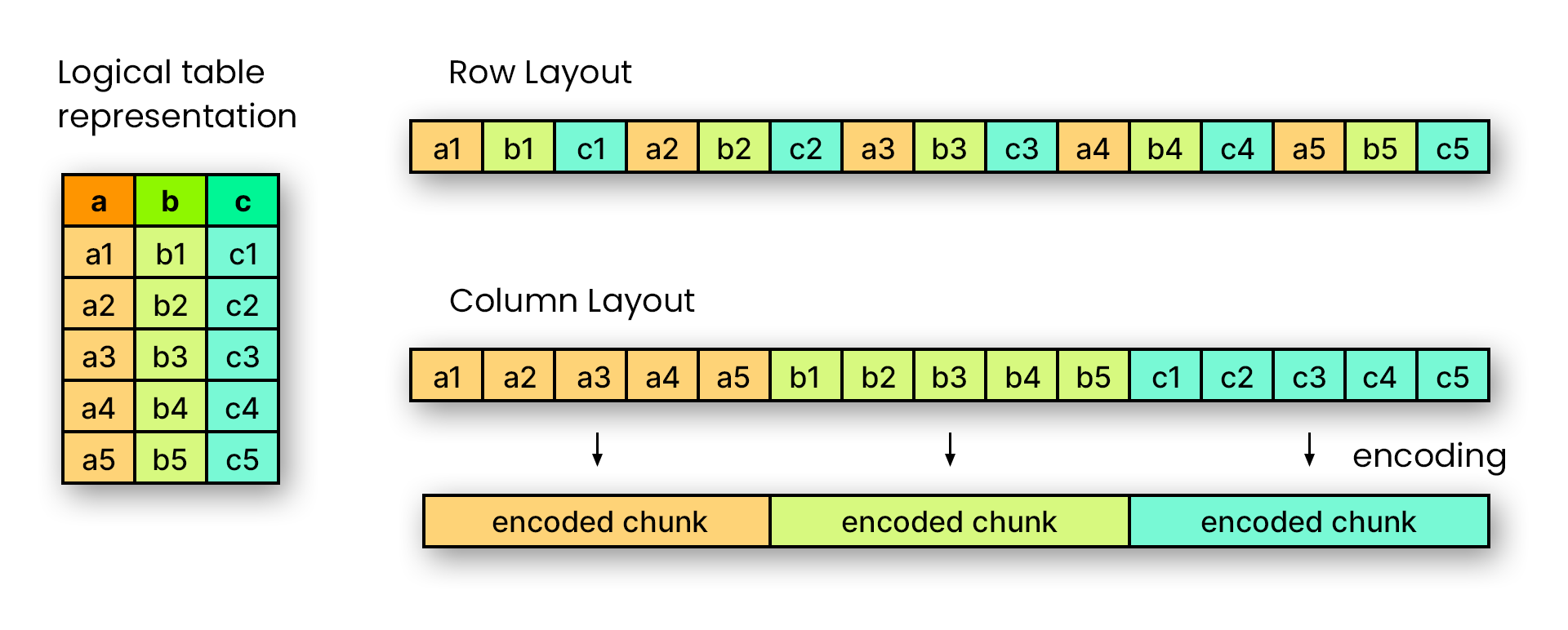
(1) csv와 parquet 비교
- csv는 콤마로 데이터를 구분하고, 행 기반 형식이며 메타정보를 포함하지 않는다.
- parquet는 열 단위로 구분하고, 메타정보를 포함하고 있기 때문에 용량이 적을 때 csv보다 데이터 용량이 클 수 있다.
🔍 메타데이터(Metadata)란?
parquet 파일 구조는 보면 헤더, 하나 이상의 블록, 꼬리말 순으로 구성된다.
모든 메타데이터는 꼬리말에 저장된다. 꼬리말 데이터는 포맷버전, 스키마, 추가 키-값 쌍, 파일의 모든 블록에 대한 메타 데이터와 같은 정보를 포함한다.
즉, 메타데이터는 데이터에 관한 구조화된 데이터로, 대량의 정보 가운데에서 확인하고자 하는 정보를 효율적으로 검색하기 위해 원시데이터(Raw data)를 일정한 규칙에 따라 구조화 혹은 표준화한 정보를 의미한다.
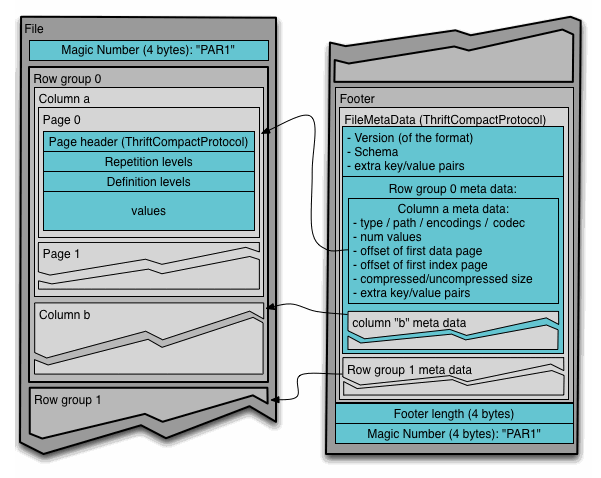
✔️ Parquet 필요성
- 저장 공간을 절약하면 비용을 줄일 수 있다.
- 클라우드 환경에 저장한다면 사용하는 용량에 따라 비용을 지불해야 한다.
- 저장 공간을 줄일수록 비용을 낮출 수 있다.
- 분석 쿼리에는 작업에 대한 열의 하위 집단만 필요한 경우가 많으므로 읽어야 하는 데이터의 양이 줄어든다.
(1) 파일 크기
- 파일 크기는 컴퓨터 파일의 크기를 측정한다.
| 이름 | 기호 | 2진 측정값 | 10진 측정값 | 바이트 수 | 같은 값 | |
|---|---|---|---|---|---|---|
| 0 | 킬로바이트 | KB | 2^10 | 10^3 | 1,024 | 1,024 바이트 |
| 1 | 메가바이트 | MB | 2^20 | 10^6 | 1,048,576 | 1,024KB |
| 2 | 기가바이트 | GB | 2^30 | 10^9 | 1,073,741,824 | 1,024MB |
| 3 | 테라바이트 | TB | 2^40 | 10^12 | 1,099,511,627,776 | 1,024GB |
| 4 | 페타바이트 | PB | 2^50 | 10^15 | 1,125,899,906,842,624 | 1,024TB |
| 5 | 엑사바이트 | EB | 2^60 | 10^18 | 1,152,921,504,606,846,976 | 1,024PB |
| 6 | 제타바이트 | ZB | 2^70 | 10^21 | 1,180,591,620,717,411,303,424 | 1,024EB |
| 7 | 요타바이트 | YB | 2^80 | 10^24 | 1,208,925,819,614,629,174,706,176 | 1,024ZB |
✔️ Parquet 저장 및 읽기
(1) 라이브러리 설치
-
pandas에서
to_parguet함수를 사용해서 데이터프레임을 parquet 포맷으로 변경할 때 사용할 수 있는 엔진의 옵션이 두 가지(fastparquet,pyarrow)가 있다. -
pandas는 내부적으로 두 라이브러리를 가져와서 parquet 파일로 변환한다.
- 라이브러리를 선택하여 저장하는 방법은 함수 내에
engine="라이브러리명"을 추가하면 된다.
- 라이브러리를 선택하여 저장하는 방법은 함수 내에
# 1. Pip 설치
!pip install fastparquet
!pip install pyarrow
# 2. Conda 가상환경 설치
conda install -c conda-forge fastparquet
conda install -c conda-forge pyarro
🚨 주의사항
- 라이브러리 버전의존성 이슈로 두 라이브러리를 설치해도 동작하지 않는 문제가 발생할 수 있다.
- 설치를 했으나 사용이 안되는 경우, 아래 명령어를 터미널 환경에 작성해 보기
- 라이브러리 삭제 후 재설치할 때, 1번이 안되면 2번으로 해 보기
# 기존에 설치했던 pyarrow 제거
pip uninstall pyarrow
# 다시 설치
pip install pyarrow # 1번 방법
python -m pip install pyarrow # 2번 방법
# 잘 설치되어있는지 버전 확인 (주피터 노트북)
pyarrow.__version__
(2) parquet 저장하기
import pandas as pd
# 저장할 파일 경로 이름
file_path_parquet = 'df.parquet.gzip'
# 데이터프레임을 parquet로 저장
df.to_parquet(file_path_parquet)
(3) parquet 읽어오기
import pandas as pd
# 저장할 파일 경로 이름
file_path_parquet = 'df.parquet.gzip'
# 데이터프레임을 parquet로 저장
pd.read_parquet(file_path_parquet)
✔️ Parquet 모니터링
- 파일 크기
- 파일 로드 시간
- 실습 데이터 : 코로나19
(1) csv와 parquet 크기 비교
- 아래 코드 결과 : {‘parquet’: ‘2.42 MB’, ‘csv’: ‘13.06 MB’}
- parquet 로 저장하면 약 5배 정도의 저장 공간을 절약할 수 있다.
import pandas as pd
import os
# 파일 크기 단위 변환 함수
def convert_bytes(num):
# bytes 부터 TB 까지 단위 설정
for file_size in ['bytes', 'KB', 'MB', 'GB', 'TB']:
if num < 1024:
return f"{num:.2f} {file_size}"
break
num /= 1024
# 파일 사이즈 반환 함수
def file_size(file_path):
# 지정한 파일에 대한 크기 반환
if os.path.isfile(file_path):
file_info = os.stat(file_path)
return convert_bytes(file_info.st_size)
# csv와 parquet 파일 크기 비교 함수
def compare_csv_parquet(df):
file_path_parquet = 'df.parquet.gzip'
file_path_csv = 'df.csv'
# 데이터프레임을 parquet, csv로 저장하고 저장된 파일 크기 반환
df.to_parquet(file_path_parquet)
df.to_csv(file_path_csv, index=False)
return {"parquet": file_size(file_path_parquet), "csv": file_size(file_path_csv)}
df = pd.read_csv("data/seoul-covid19-2021-12-18.csv")
compare_csv_parquet(df)
(2) csv와 parquet 파일로드 후, info 실행 시간 비교

🔍 %timeit 으로 10번 반복 실행했을 때 소요된 평균 시간
csv: 158 ms ± 576 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)parquet: 83.2 ms ± 179 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
✔️ Reference
- 멋쟁이사자처럼 AI SCHOOL 박조은 강사님 강의 자료
- 📷 Fig 1 출처 : dremio - What is Apache Parquet?
- 📷 Fig 2 출처 : Apache Parquet 공식문서 - File Format
- 위키백과, 우리 모두의 백과사전 - Apache Parquet
- 위키백과, 우리 모두의 백과사전 - 파일 크기
- 티스토리 by 카프리썬 - 🌲Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기
- 티스토리 by devidea - Parquet (파케이)
- Metafor - [에러로그]parquet파일 변환 fastparquet v.s pyarrow
개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다 :)
댓글남기기