
[TIL] 랜덤 포레스트(Random Forest) 모델 해석
랜덤 포레스트(Random Forest, RF)는 성능이 뛰어나고 예측을 만드는 연산 과정을 쉽게 확인할 수 있으나, 왜 그러한 예측을 만드는지를 설명하기 어려운 모델이다. 랜덤 포레스트 모델의 단일 결정트리를 추출하여 노드가 분할되는 과정과 feature importance를 시각화해 본다.
시각화를 위해 사용한 데이터셋은 Kaggle Datasets ‘Pima Indians Diabetes Database’이고 실습은 Jupyter notebook에서 진행하였다.
1. 데이터 준비
랜덤 포레스트의 단일 결정 트리를 추출하여 시각화해 보기 위해 Kaggle의 ‘Pima Indians Diabetes Database’ 데이터셋을 사용하였다.
# 기본적으로 잘 사용하는 라이브러리 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 로드
df = pd.read_csv('../Data/pima_indians_diabetes.csv')
피마 데이터셋의 크기(df.shape)는 ((768, 9)) 이다. 데이터는 9개의 컬럼으로 이루어져있는데 각 컬럼별 의미는 다음과 같다.
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
위 컬럼들 중에서 Outcome이 예측해야되는 결과 클래스이다.
(1) 데이터 요약
1-1. 일부 출력
1-2. 요약
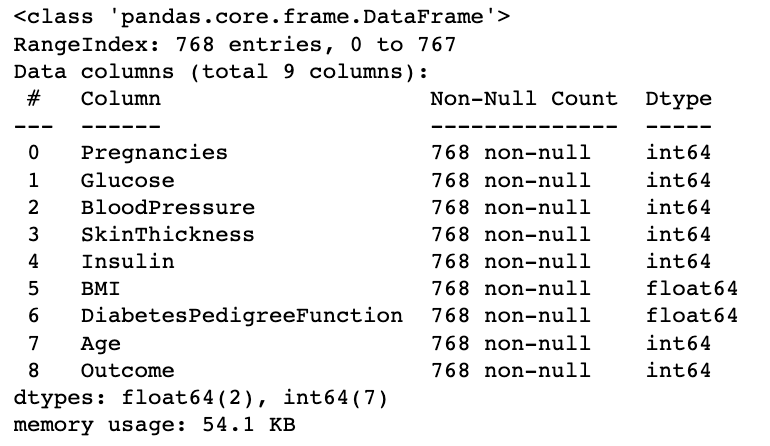
누락된 데이터는 없어보인다. 그리고 모든 데이터가 수치형 데이터이다.
1-3. 기술통계
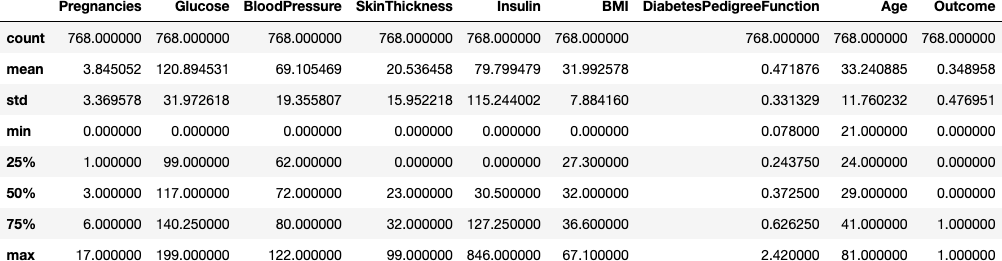
1-4. 히스토그램
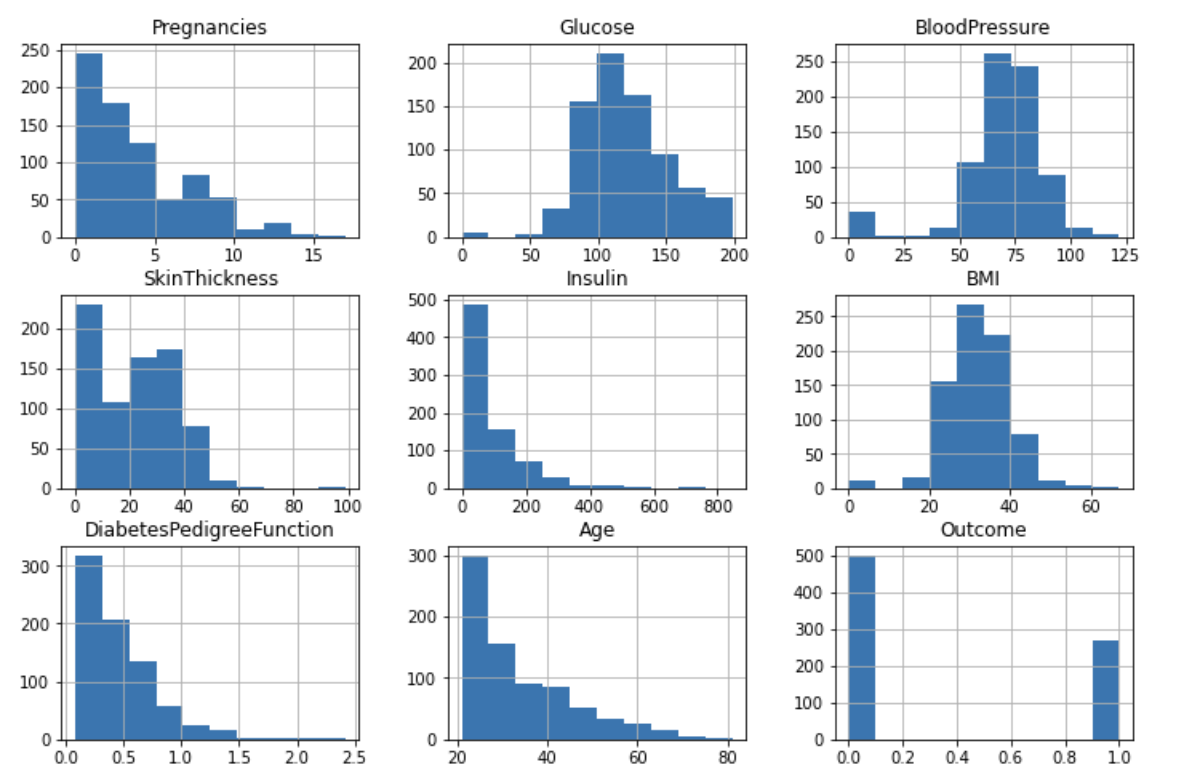
Pregnancies, Insulin, DiabetesPredigreeFuncion, Age에 대한 히스토그램 결과를 보면 왼쪽으로 치우친 형태임을 알 수 있다. 값이 0 또는 20(Age)에 많이 치우져 있음을 알 수 있다.
2. 데이터셋 분할(학습, 테스트)
학습용 데이터셋과 테스트용 데이터셋은 8:2 비율로 나누었다. 데이터셋을 나누는 과정은 다음과 같다.
# 80:20 을 기준으로 나누는 분할 포인트를 지정한다.
split_idx = int(df.shape[0] * 0.8)
# train, test 용 데이터셋을 슬라이싱으로 나눈다.
train = df[:split_idx]
test = df[split_idx:]
그리고 예측해야할 값과 예측에 사용할 값(feature)을 나눈다.
# 학습, 예측에 사용할 컬럼 정의한다(예측해야하는 컬럼값을 제거).
feature_names = df.columns.tolist()
feature_names.remove("Outcome")
# 예측해야할 컬럼값을 label_name 변수에 지정한다.
label_name = "Outcome"
X, y로 각각의 학습, 예측용 데이터셋을 만든다.
# 학습용 X, y
X_train = train[feature_names]
y_train = train[label_name]
# 예측용 X, y
X_test = test[feature_names]
y_test = test[label_name]
X_train, y_train, X_test, y_test의 shape 값을 출력해 보면 ((614, 8), (614,), (154, 8), (154,)) 로 잘 나누어진 것을 알 수 있다.
3. 모델 생성
랜덤포레스트와 같은 Decision Tree 계열의 모델은 스케일링 과정을 별도로 해주지 않아도 된다(노드가 분할되며 모델이 구축될 때 각각의 피처가 사용되기 때문). 랜덤 포레스트 머신러닝 알고리즘은 sklearn 패키지에서 제공하는 것을 사용하였다.
# sklearn에서 제공하는 랜덤 포레스트 모델을 가져온다.
from sklearn.ensemble import RandomForestClassifier
# 모델은 결정 트리 10개를 랜덤하게 생성, 최대 깊이를 3개로 제한, random_state를 42로 지정하였다.
rf = RandomForestClassifier(n_estimators=10, max_depth=3, random_state=42)
# X_train, y_train 값으로 모델을 학습한다.
rf.fit(X_train, y_train)
# test 데이터셋에 대해 모델이 예측한 값을 저장한다.
y_predict = rf.predict(X_test)
(1) 모델 평가
분류 모델을 평가하기 위해 Accuracy(정확도), Precision(정밀도), Recall(재현율), F1 Score을 구해보았다.
# sklearn에는 여러 평가지표를 미리 정의하여 제공하고 있다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 각 평가지표에 따른 성능 평가 결과를 출력한다.
print(f'Accuracy: {accuracy_score(y_test, y_predict)}')
print(f'Precision: {precision_score(y_test, y_predict)}')
print(f'Recall: {recall_score(y_test, y_predict)}')
print(f'F1 score: {f1_score(y_test, y_predict)}')
Accuracy: 0.7532467532467533
Precision: 0.7428571428571429
Recall: 0.4727272727272727
F1 score: 0.5777777777777778
모델의 결과를 분석해 보면 정확도가 약 75%로 높지 않은 편이다. 특히 눈에 띄는 값이 Recall 값인데 1에 가까울 수록 좋은 성능임을 나타내는 값이 50%보다 낮게 측정되었다. Recall 은 실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율이다(실제 정답이 positive인 데이터를 negative라고 잘못 예측하면 안 되는 경우에 중요한 지표가 될 수 있다). Recall 값이 작다는 것은 모델이 negative라고 예측했는데 정답이 positive인 경우가 많다는 뜻이다. TP, TN, FP, FN 을 시각적으로 확인하기 위해 Confusion Matrix를 시각화해 보았다.
s = sns.heatmap(confusion_matrix(y_test, y_predict), annot=True)
s.set(xlabel="Predict", ylabel="True");
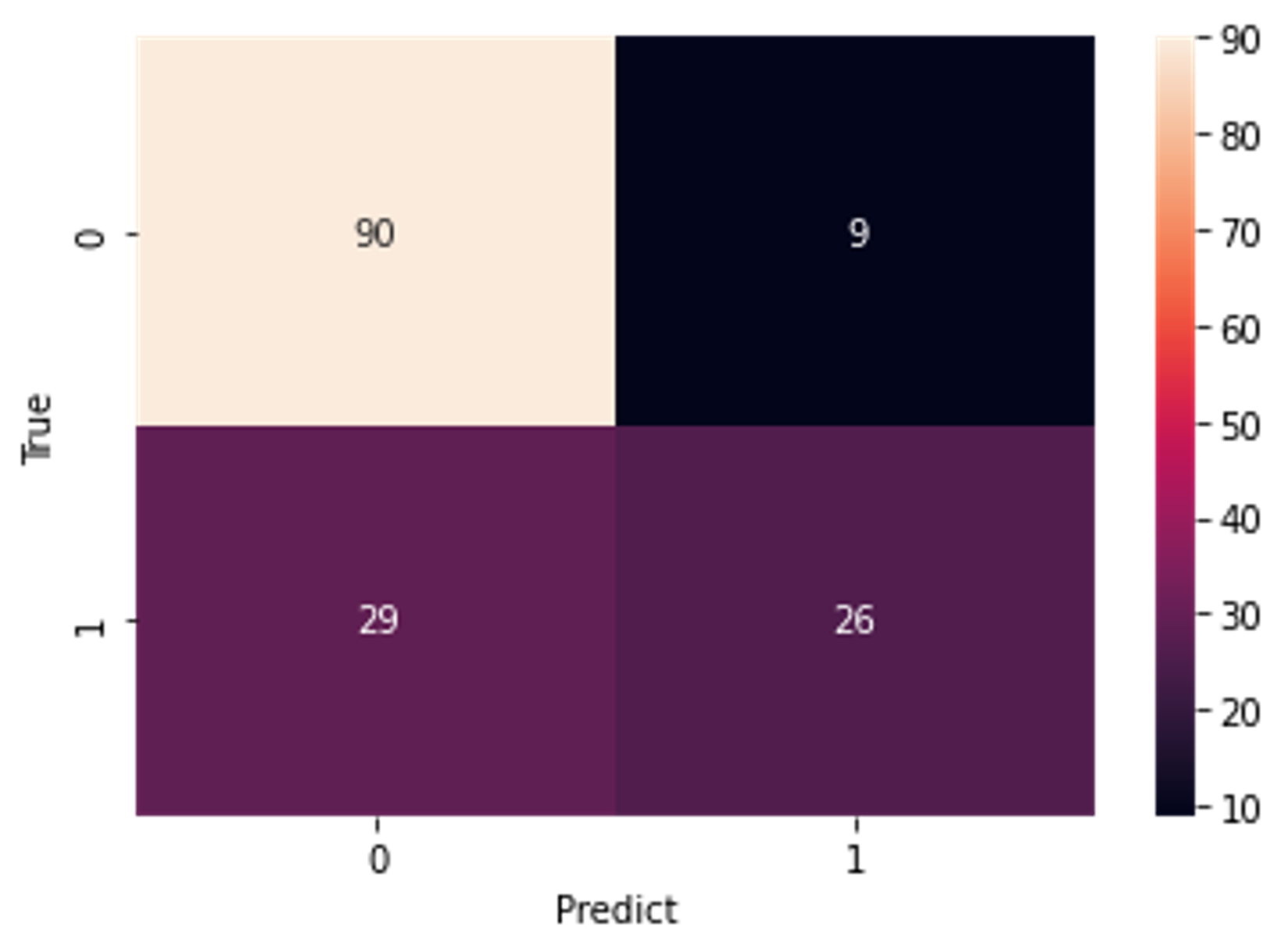
실제로 Outcome 값이 0인데 0으로 잘 예측한 경우는 90개이다. df['Outcome'].value_counts() 값을 확인해 보면 기존 데이터셋엔 Outcome이 0인 데이터는 500개, 1인 데이터는 268개로 0인 데이터가 약 2배 더 많다. 이 부분도 예측에 크게 작용했을 것으로 보인다(데이터 불균형).
실제로 Outcome 값이 1인 데이터를 약 반반의 비율로 맞고 틀림(29(틀림):26(맞음))
(2) 모델 해석
랜덤 포레스트 모델은 여러 결정 트리를 생성하고 각 트리에서의 결과값을 평균내어 값을 예측한다. 이때 전체 트리에 대해 시각적으로 확인할 수 없지만, 단일 결정트리를 추출하여 대표로 시각화해 볼 수 있다. 방법은 다음과 같다.
# 랜덤 포레스트로 생성된 각각의 결정 트리가 리스트에 담겨있다.
rf.estimators_
[DecisionTreeClassifier(max_depth=3, max_features='auto',
random_state=1608637542),
DecisionTreeClassifier(max_depth=3, max_features='auto',
random_state=1273642419),
DecisionTreeClassifier(max_depth=3, max_features='auto',
random_state=1935803228),
DecisionTreeClassifier(max_depth=3, max_features='auto', random_state=787846414),
DecisionTreeClassifier(max_depth=3, max_features='auto', random_state=996406378),
DecisionTreeClassifier(max_depth=3, max_features='auto',
random_state=1201263687),
DecisionTreeClassifier(max_depth=3, max_features='auto', random_state=423734972),
DecisionTreeClassifier(max_depth=3, max_features='auto', random_state=415968276),
DecisionTreeClassifier(max_depth=3, max_features='auto', random_state=670094950),
DecisionTreeClassifier(max_depth=3, max_features='auto',
random_state=1914837113)]
모델엔 estimators_ 라는 속성을 사용하여 생성된 모델의 리스트(집합)을 확인할 수 있다. 여기서 하나의 모델을 가져와 시각화하면 된다.
# sklearn에선 결정 트리를 시각화할 수 있는 함수를 정의해두었다.
from sklearn.tree import plot_tree
# 여러 단일 결정 트리 중 리스트의 첫 번째에 위치한 것을 시각화한다.
plt.figure(figsize=(15, 10))
plot_tree(rf.estimators_[0], feature_names=feature_names);
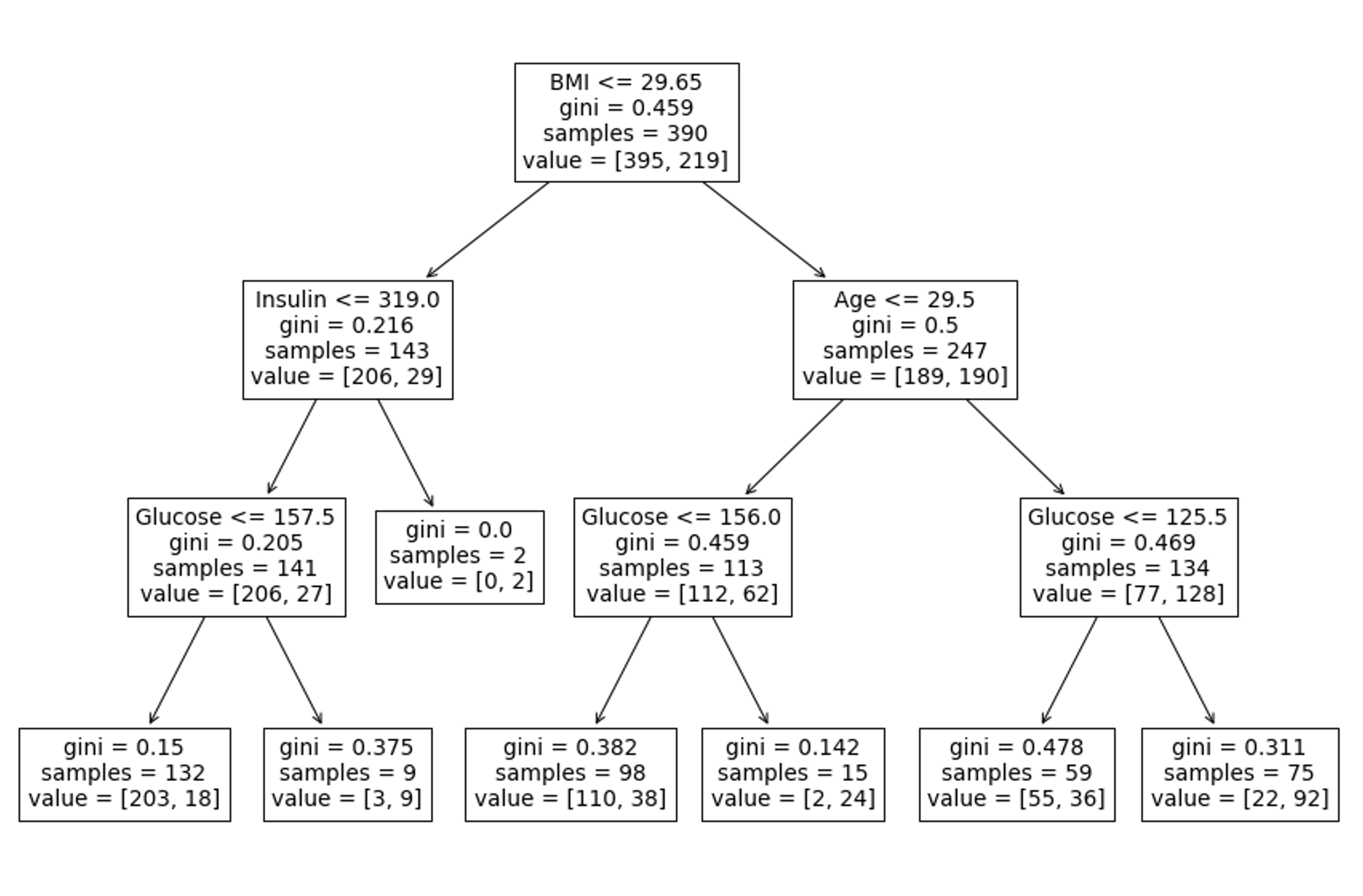
위 코드를 보면 plt.figure 를 사용하여 따로 이미지의 크기를 조정하였는데 이는 plot_tree 함수가 별도의 figsize를 지원하지 않기 때문이다.
트리를 시각화한 것을 보면 모델에 따로 criterion을 지정하지 않았기 때문에 기본값으로 gini 불순도를 기준으로 각 노드별 불순도를 측정한다.
이처럼 랜덤포레스트의 estimators_ 속성을 사용하면 생성된 트리를 하나씩 불러와서 시각적으로 확인해 볼 수 있다.
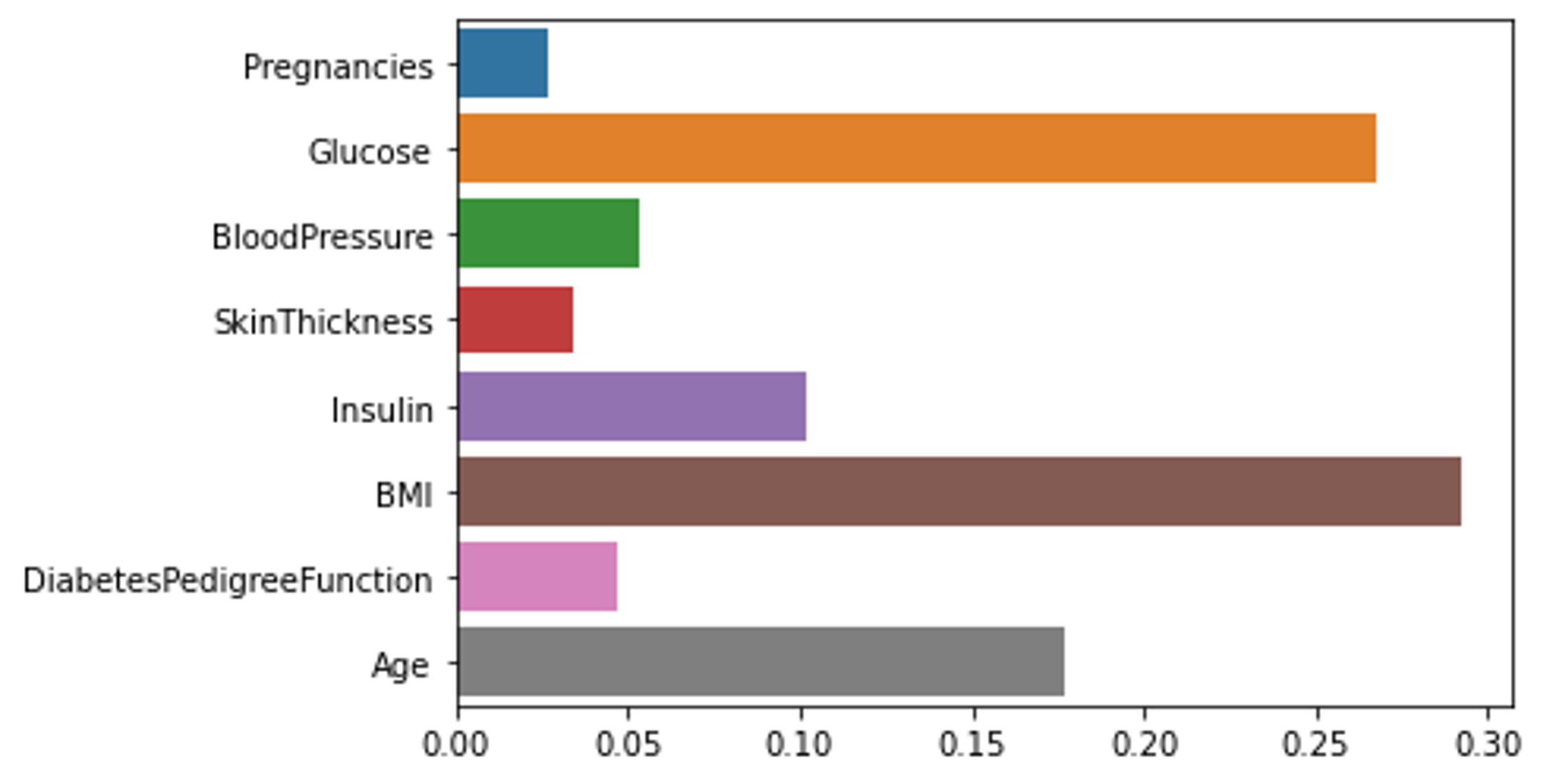
(3) Feature importance
랜덤 포레스트(결정 트리들의 집합)의 Feature importance 값은 아래와 같이 시각화할 수 있다.
# 랜덤포레스트의 피쳐 중요도를 시각화한다.
sns.barplot(x=rf.feature_importances_, y=rf.feature_names_in_);
# 포레스트에 구성된 단일 트리의 피쳐 중요도를 시각화한다.
sns.barplot(x=rf.estimators_[0].feature_importances_, y=rf.feature_names_in_);
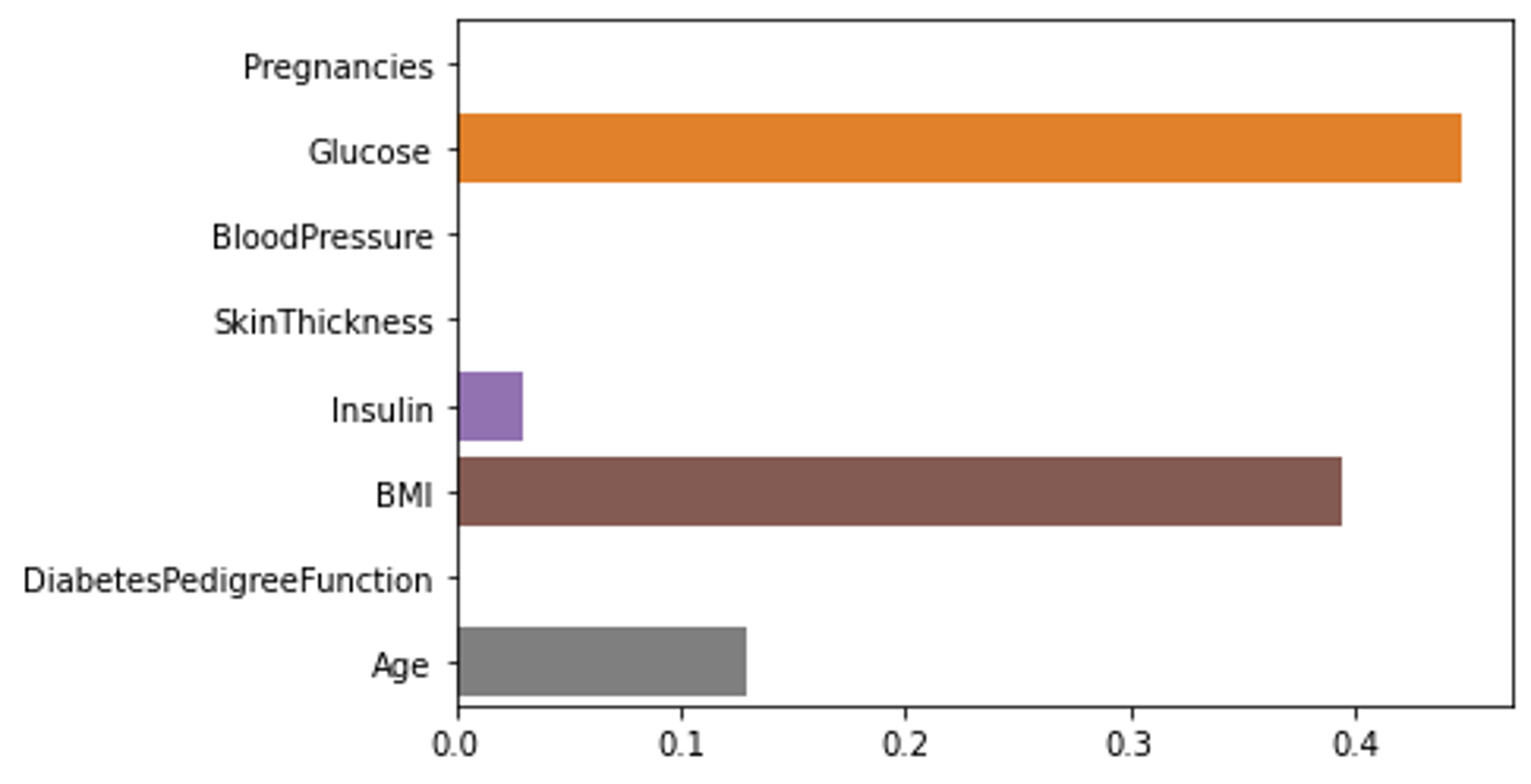
랜덤 포레스트 자체의 feature importances를 시각화하면 전체 결정 트리들의 집합에 대한 종합된 결과이고 단일 결정 트리에 대한 피쳐 중요도를 시각화해 보면 트리의 노드를 분할할 때 사용된 Feature만 측정되어 기록되어있음을 알 수 있다.
4. 마무리
랜덤 포레스트는 결정 트리를 랜덤하게 n_estimators 만큼 생성하고 각각의 트리에서 예측한 값을 평균내어 반환하게 된다. 이때 모델에 estimators_ 라는 속성을 사용하면 생성된 각각의 단일 결정 트리를 하나씩 불러올 수 있는데 이 것을 사용하면 각각의 트리에 대한 노드 분할 과정, feature importance를 시각적으로 확인할 수 있다. 과대적합 등의 이슈를 이유로 DecisionTree 대신 RandomForest를 사용해도 트리를 시각화할 수 있다. 위와 같은 방법으로 숲을 구성하는 각각의 트리를 시각화하여 나무에서 숲으로의 해석을 해 보는 것도 좋을 것같다.
5. Reference
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기