
[Seaborn] mpg 데이터셋의 수치형 데이터 시각화하기 (1)
파이썬 시각화 라이브러리, Seaborn ‘mpg’의 수치형 데이터 시각화하기
1. 학습 목표
- seaborn의 mpg 데이터셋을 이용하여 수치형 변수에 대해 시각화
- 히스토그램, displot, kdeplot, rugplot, boxplot, violinplot 그려보기
- 스케일링에 대해 이해하기
2. 라이브러리, 데이터 로드
# 라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn 내장 데이터셋인 'mpg' 데이터를 df에 저장
df = sns.load_dataset("mpg")
3. 데이터 살펴보기
(1) 데이터 구조
# 데이터셋 구조 파악
df.shape
>> (398, 9)
(2) 데이터 형태
# 상위 5개 데이터만 불러오기
df.head()
# 하위 5개 데이터만 불러오기
df.tail()
(3) 데이터 요약
# 데이터 기본 정보 요약
df.info()

- 데이터셋은 총 398개의 데이터를 가지고 있다.
- origin, name은 type이 object 이다.
- 데이터 타입, 결측치의 유무, 메모리 사용량 등의 정보를 알 수 있다.
- horsepower 에 결측치가 존재한다.
(4) 결측치
- print(plt.colormaps()) : colormap 종류 확인
- coolwarm : heatmap에서 한눈에 파악하기 좋은 컬러
- Sequential, Diverging, Cyclinc 등 다양한 상황에서 색상 적용할 수 있음
plt.figure(figsize=(6, 4))
sns.heatmap(df.isnull(), cmap="gray")
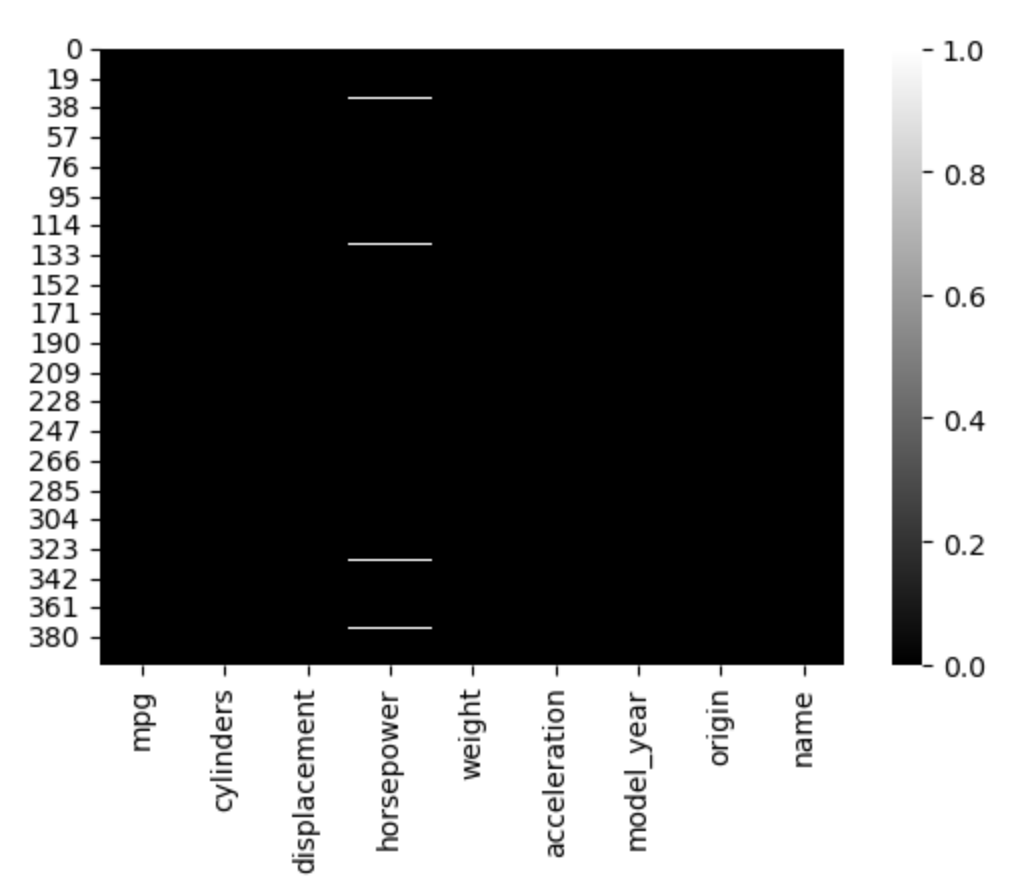
- 그래프에서 y축(왼) : 데이터 인덱스 번호 / x축 : 컬럼명 을 나타낸다.
- mpg 데이터셋에서 결측치는 horsepower에서 총 6개 존재한다.
(5) 기술통계
# 데이터 기술 통계값(수치형)
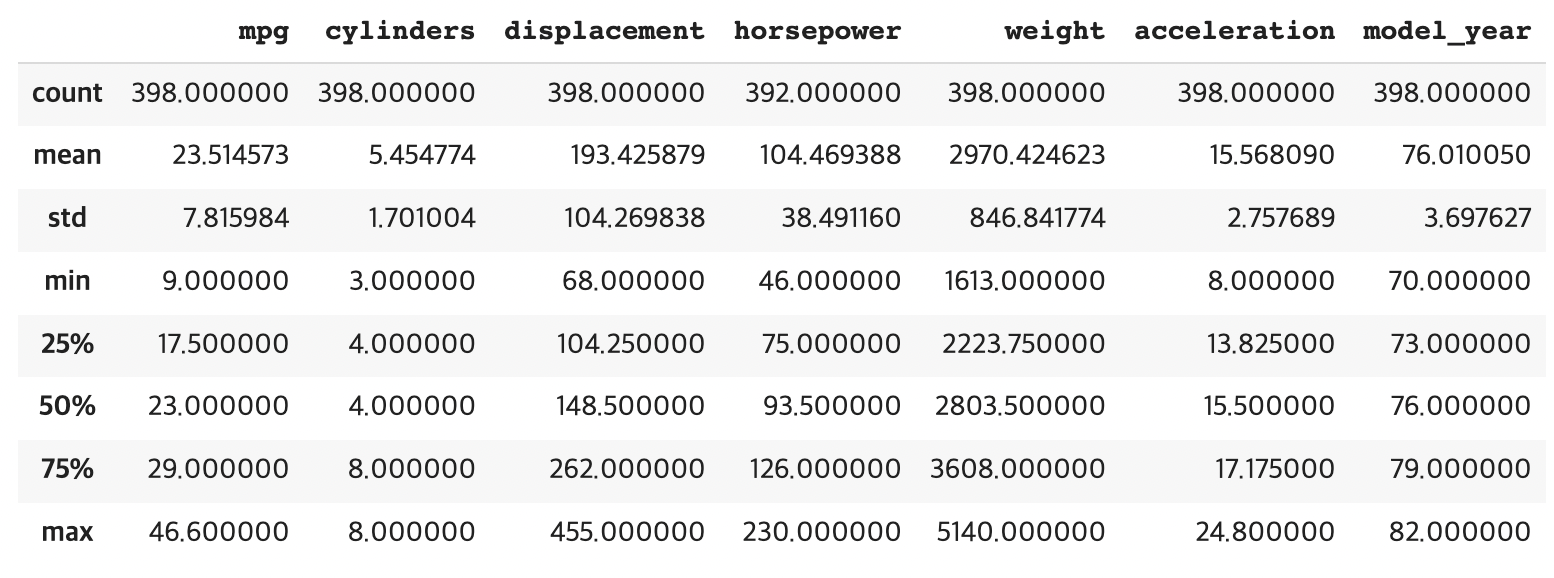
df.describe()
# 데이터 기술 통계값(범주형)
df.describe()
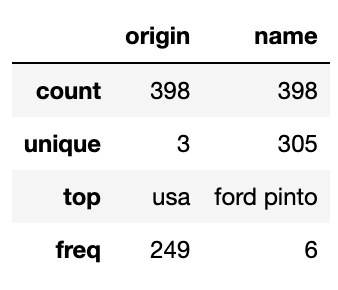
(6) 유일값
# 데이터 unique 개수
df.nunique()
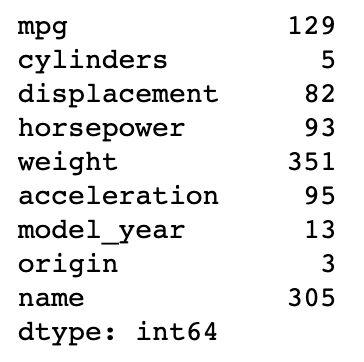
- cylinders, model_year, origin 의 유일값을 보면 전체 데이터 개수(398개)에 비해 매우 적다.
- 수치형 변수이지만 범주형 변수에 가깝다고 생각할 수 있다.
4. 데이터 시각화
🔍 수치형 데이터(numberical data)
- 관측된 값이 수치로 측정되는 자료를 말한다.
- 양적 자료(quantitative data)라고도 불린다.
- 관측되는 값의 성질에 따라 연속형 자료(continuous data), 이산형 자료(discrete data)로 구분된다.
(1) 히스토그램
hist : 각 변수에 대한 따른 y축(count) 관계이다.
bins : 막대그래프의 개수이다.
# 막대 개수 50개로 설정
df.hist(figsize=(12, 10), bins=50)
plt.show()
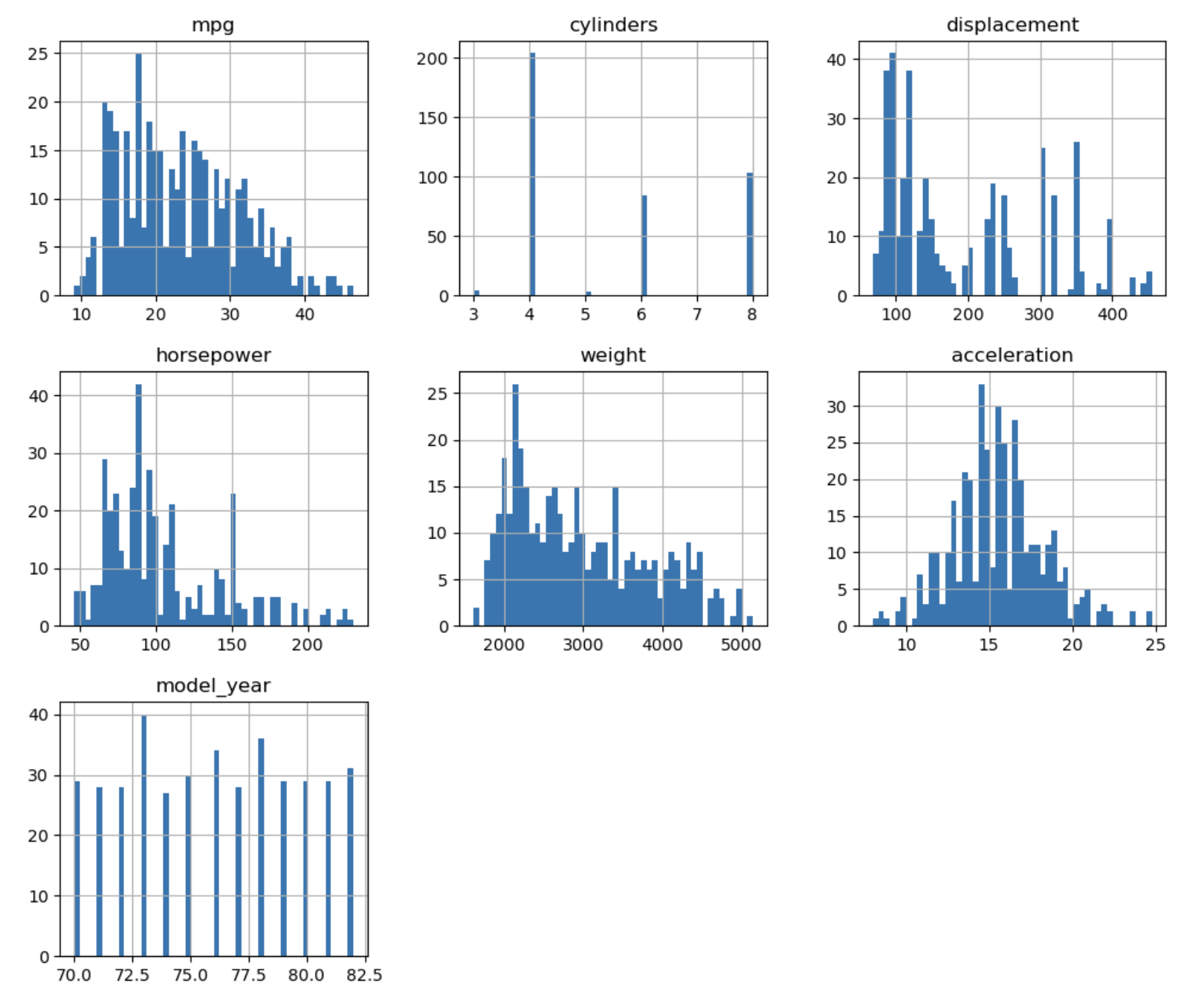
🔍 그래프 해석
- cylinders 는 범주형 데이터로 볼 수 있다.
- mpg, displacement, horsepower, weight 는 왼쪽으로 치우쳐있다.
- acceleration 은 15를 기준으로 대칭성을 보인다.
- 수치형 데이터로 시각화 해 볼 column은 mpg, displacement, horsepower, weight 이다.
(2) Displot
- Displot: 히스토그램과 kdeplot을 동시에 그릴 수 있는 그래프
- y축 기본값 : 개수(count)
- hue : 설정한 값에 대해 색상 부여
- col : 설정한 값에 대해 subplot 생성
# hist, kde 그래프를 한번에 그리기
sns.displot(data=df, x="mpg", kde=True)
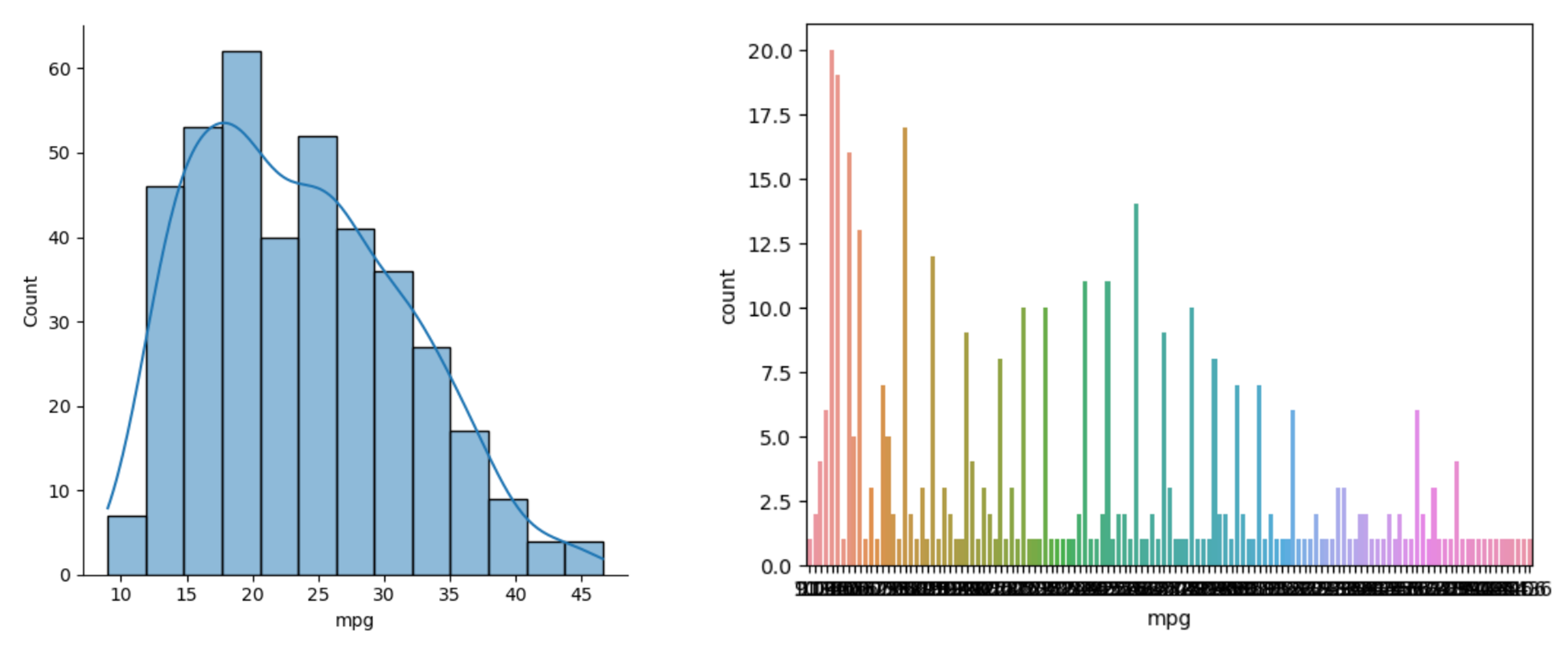
- 수치형 데이터를 countplot으로 그리기엔 적절하지 않다.
- 연속형 변수에 대해서 x축에 모든 값이 포함되기 때문
- 수치형 데이터의 범위별 count 값을 확인하고자할 때 displot 을 사용하면 된다.
# hist, kde 그래프를 한번에 그리기
# origin에 대해 subplot 생성
sns.displot(data=df, x="mpg", kde=True,
hue="origin", col="origin", bins=30)
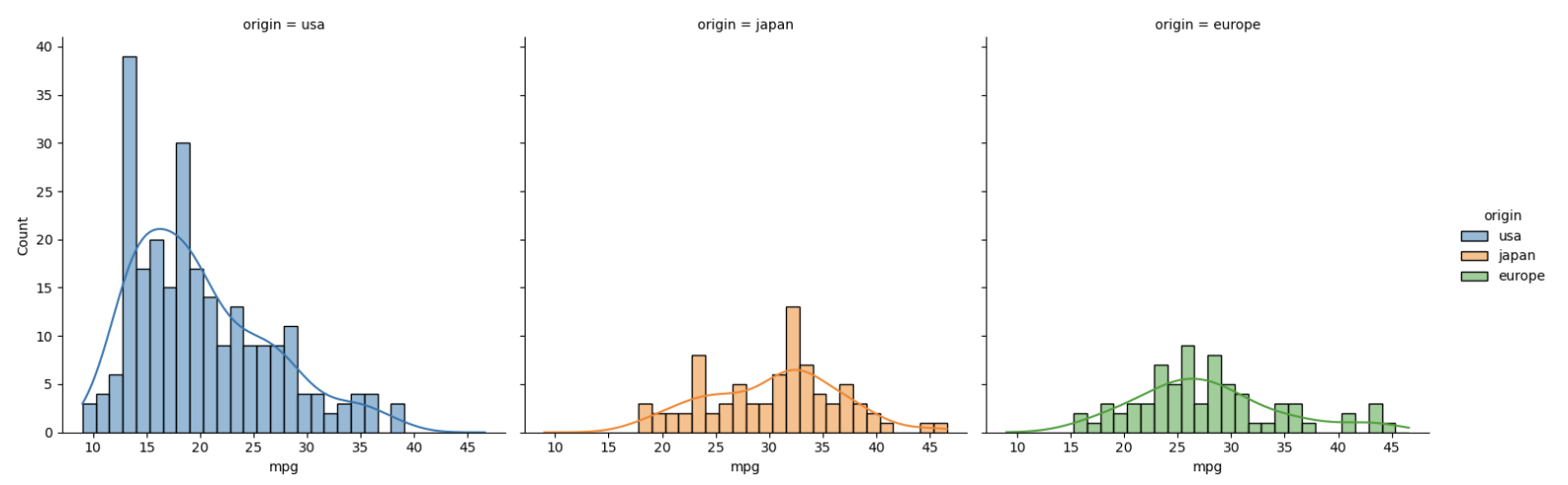
kde=False(default)일 땐 히스토그램과 같은 그래프가 그려진다.- 전체 데이터에 대한 연비는 약 10 ~ 45 범위에서 왼쪽으로 치우쳐져 있다. (positive skewness)
- usa : 연비는 10~25 사이로 치우쳐져 있다.
- europe에 대한 연비는 정규 분포에 가깝다는 것을 알 수 있다.
(3) Kdeplot, Rugplot
KDE(Kernel Density Estimate)
- 관측치에 대한 확률밀도함수를 그림 (히스토그램의 밀도를 추정한 것)
- y축 기본값 : 밀도(Density)
RUG(선분)
- 작은 선분(rug)으로 데이터들의 위치 및 분포를 보여줌
# kdeplot
sns.kdeplot(data=df, x="mpg")
# rugplot
sns.rugplot(data=df, x="mpg")
# kde + rug plot
sns.kdeplot(data=df, x="mpg")
sns.rugplot(data=df, x="mpg")
- kdeplot, rugplot으로 어디에 데이터가 몰려있는지 알 수 있다.
- violinplot : kdeplot을 x축을 기준으로 데칼코마니 한 모양
(4) Boxplot, Violinplot
boxplot : 사분위 수, 이상치를 나타내는 그래프
violinplot : kdeplot을 마주보고 그린 그래프(그래프에서 흰 점, 중간값)
# boxplot으로 전체 변수 시각화
sns.boxplot(data=df)
# violinplot으로 전체 변수 시각화
sns.violinplot(data=df)

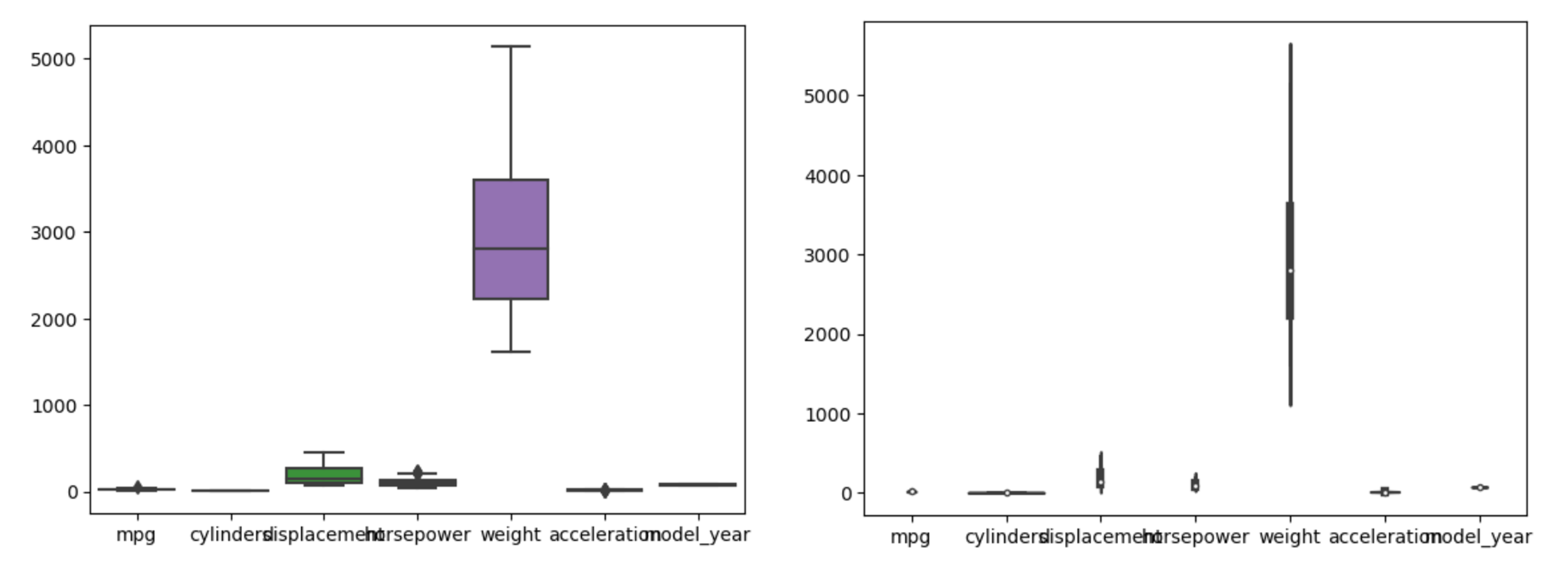
- 전체 변수에 대해 시각화를 해보면 범위가 커서 그래프가 전달하고자하는 의미를 파악하기 힘들다.
- 범위를 스케일링하여 위 문제를 해결해보자.
🔍 스케일링
모든 특성의 범위(또는 분포)를 같게 만드는 것으로 주로 사용되는 스케일링 개념은 아래와 같다.
(1) Standardization (표준화)
- 특성들의 평균을 0, 분산을 1로 스케일링하는 것
- 즉, 특성들을 정규분포로 만드는 것
(2) Normalization (정규화)
- 특성들을 특정 범위 (주로 [0, 1]) 로 스케일 하는 것
- 가장 작은 값은 0, 가장 큰 값은 1로 변환되므로, 모든 특성들은 [0, 1] 범위를 갖게 됨
🔍 스케일링 과정(표준화)
# 수치형 데이터를 변수 df_num에 할당
df_num = df.select_dtypes(include="number")
# 정규화 : (관측치 - 평균) / 표준편차
df_std = (df_num - df_num.mean())/df_num.std()
# 정규화 후, 전체 변수에 대한 기술통계값 확인 (소수점 2자리까지)
df_std.describe().round(2)
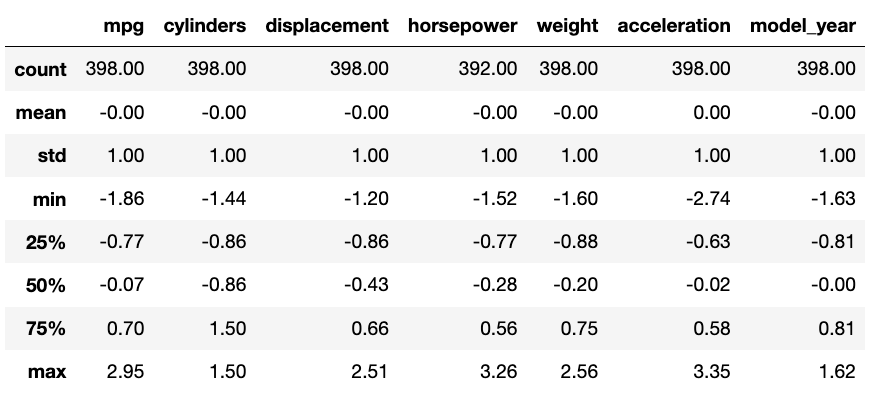
🔍 정규화된 변수에 대한 밀도함수
# boxplot으로 전체 변수 시각화
sns.boxplot(data=df_std)
# Violinplot으로 전체 변수 시각화
sns.violinplot(data=df_std)
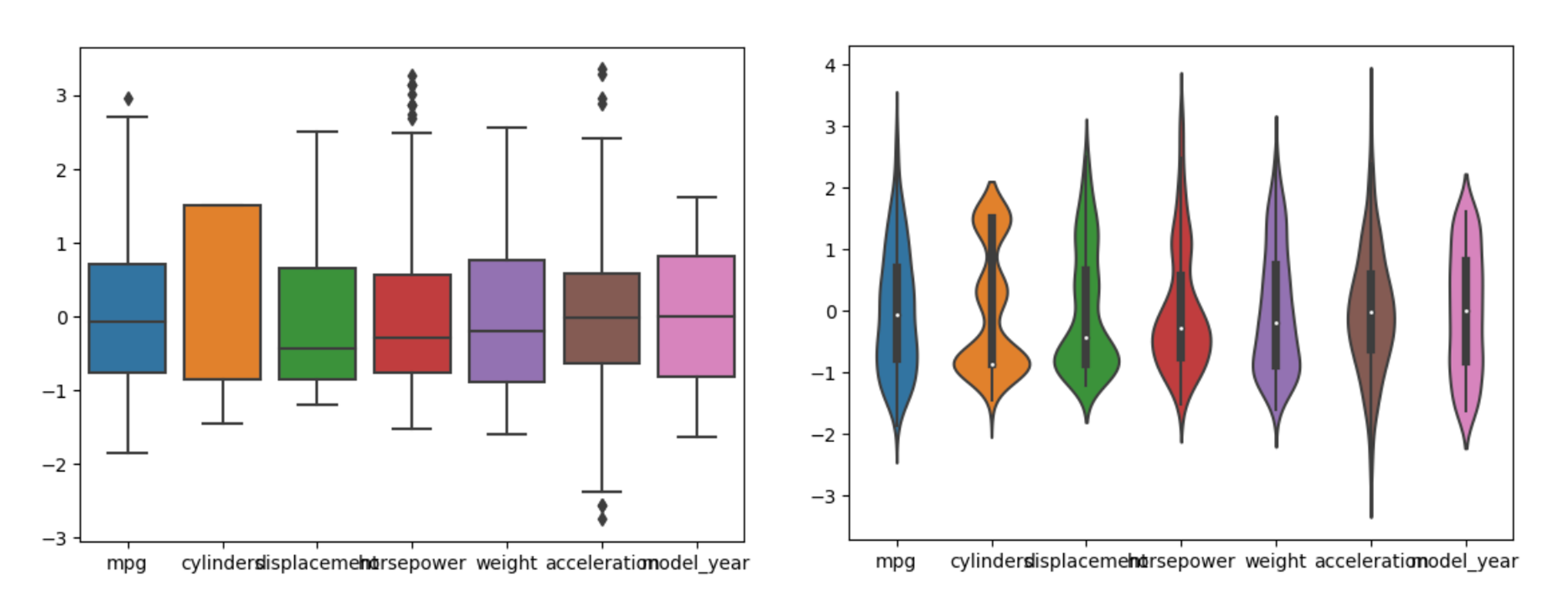
- 범위가 중구난방인 변수를 스케일링 하게 되면, 위와 같이 그래프가 한 눈에 파악하기 쉬워진다.
- 특히, violinplot 을 보면, 값의 분포를 더 잘 확인할 수 있다.
5. 회고
주어진 데이터가 수치형인지 범주형인지 판단하는 방법을 배웠다. dtype이 object가 아닌 경우에도 범주형 데이터로 취급하는 경우가 있다. 이는 unique 값을 구해보거나 histogram을 그려보면 알 수 있다.
- 히스토그램을 그려보았을 때, 연속적이지 않고 뚝뚝 끊기는 경우엔 그 변수를 범주형 변수에 가깝다고 생각할 수 있다.
- 이번에 그려본 히스토그램, kdeplot, displot, 등의 그래프는 1개의 변수에 대한 count, 밀도, 사분위 등을 의미했다.
- 다음엔 2개 이상의 변수에 대한 상관 관계를 알아보기 위해 scatterplot, 회귀 등을 시각화해 보아야겠다.
boxplot과 violinplot은 전체 변수를 모아서 한 그래프로 볼 수 있다. 하지만 범위가 준구난방이라면 한 그래프에 담게 되었을 때, 어떤 의미를 담고있는지 파악하기 힘들다. 이럴 땐, 범위를 스케일링하여 그래프를 보기 쉽게, 이해하기 쉽게 만들 수 있도록 여러 실습을 통해 감을 익혀야겠다.
6. Reference
- matplotlib 공식문서, Choosing Colormaps in Matplotlib
- seaborn 공식문서, Overview of seaborn plotting functions
- 위키백과, 비대칭도
- 위키백과, 첨도
- 위키백과, 상자 수염 그림
- 티스토리 by 우노, [ML] 데이터 스케일링 (Data Scaling) 이란?
- 티스토리 by 슈퍼짱짱, [기초통계] 수치형 자료(numerical data)와 범주형 자료(categorical data)
👩🏻💻개인 공부 기록용 블로그입니다
오류나 틀린 부분이 있을 경우 댓글 혹은 메일로 따끔하게 지적해주시면 감사하겠습니다.
댓글남기기